I’m trying to fit a module to my dataframe but im getting could not convert string to float: '2,550,000,000' error. please take a look at my codes below:
import tensorflow as tf
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.compose import make_column_transformer
from sklearn.preprocessing import MinMaxScaler, OneHotEncoder
from sklearn.model_selection import train_test_split
houseprice = pd.read_csv('houseprice.csv')
houseprice = houseprice.drop("Price", axis=1)
print(houseprice)
the outcome of the Print(houseprice) is this: 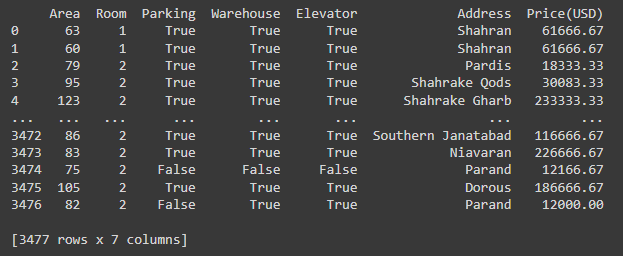
here is the rest of my code that i’m getting the error in this part
# creating X and y (test set and train set)
ct = make_column_transformer(
(MinMaxScaler(), ["Area", "Room"]),
(OneHotEncoder(handle_unknown="ignore"), ["Parking", "Warehouse", "Elevator", "Address"])
)
X = houseprice.drop("Price(USD)", axis=1)
y = houseprice["Price(USD)"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
ct.fit(X_train)
and here is a picture of my error (im trying to compile it in google colab but im getting this error in vscode too):
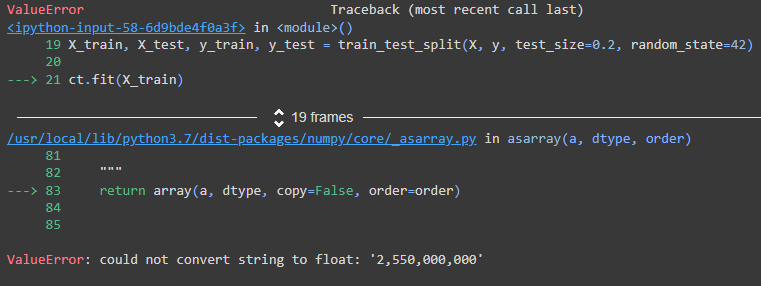
I would appreciate if someone can help me
>Solution :
You can specify the thousands separator when you read the file like this:
houseprice = pd.read_csv('houseprice.csv', thousands=',')