Advertisements
This is probably answered elsewhere but I cant figure out the phrasing to look for.
I have data like this:
df<-structure(list(PROTOCOL_ID = c(124, 124, 38, 762, 74, 146), PROGRAM_AREA = c("LOCR",
"CRC", "LOCR", "Pedi", "LOCR", "LOCR")), row.names = c(NA, 6L
), class = "data.frame")
As you can see, two rows have the same "protocol_id", they’re both 124 (lots of rows in the real data have identical numbers). Well, what I’d like to do is put the program areas for 124 on the same row. I’m ok with this being one of two ways, either like this:
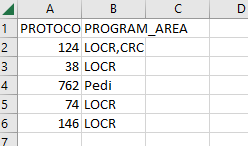
or like this:
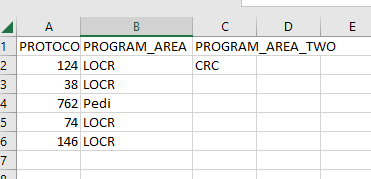
Whatever is easiest. Any suggestions would be appreciated!
>Solution :
We could use
library(dplyr) # version >= 1.1.0
df %>%
reframe(PROGRAM_AREA = toString(PROGRAM_AREA), .by = PROTOCOL_ID)
PROTOCOL_ID PROGRAM_AREA
1 124 LOCR, CRC
2 38 LOCR
3 762 Pedi
4 74 LOCR
5 146 LOCR
Or for the second case
library(tidyr)
library(data.table)
library(english)
df %>%
mutate(rn = toupper(as.character(english(rowid(PROTOCOL_ID))))) %>%
pivot_wider(names_from = rn, values_from = PROGRAM_AREA,
names_prefix = "PROGRAM_AREA_")
# A tibble: 5 × 3
PROTOCOL_ID PROGRAM_AREA_ONE PROGRAM_AREA_TWO
<dbl> <chr> <chr>
1 124 LOCR CRC
2 38 LOCR <NA>
3 762 Pedi <NA>
4 74 LOCR <NA>
5 146 LOCR <NA>