I have a dataframe like as below
import numpy as np
import pandas as pd
from numpy.random import default_rng
rng = default_rng(100)
cdf = pd.DataFrame({'Id':[1,2,3,4,5],
'customer': rng.choice(list('ACD'),size=(5)),
'segment': rng.choice(list('PQRS'),size=(5)),
'manager': rng.choice(list('QWER'),size=(5)),
'dumma': rng.choice((1234),size=(5)),
'damma': rng.choice((1234),size=(5))
})
I would like to do the below
a) create an excel file output with multiple sheets (based on segment column) for each manager (based on manager column)
b) For segment values – Q,P and S, check whether column dumma value is greater than column damma value
c) Instead of out.xlsx, save each file using the {manager}.xlsx name (from manager column)
d) If there are no records for any specific segment (len=0), then we need not create sheet for that segment
So, I tried the below
DPM_col = "manager"
SEG_col = "segment"
for i,j in dict.fromkeys(zip(cdf[DPM_col], cdf[SEG_col])).keys():
print("i is ", i)
print("j is ", j)
data_output = cdf.query(f"{DPM_col} == @i & {SEG_col} == @j")
writer = pd.ExcelWriter('out.xlsx', engine='xlsxwriter')
if len(data_output[data_output['segment'].isin(['Q','P','S'])])>0:
if len(data_output[data_output['dumma'] >= data_output['damma']])>0:
for seg, v in data_output.groupby(['segment']):
v.to_excel(writer, sheet_name=f"POS_decline_{seg}",index=False)
writer.save()
else:
for seg, v in data_output.groupby(['segment']):
v.to_excel(writer, sheet_name=f"silent_inactive_{seg}",index=False)
writer.save()
But it doesn’t work. It only shows the value for R segment (which is in else clause)
I expect my output for each manager file to have multiple sheets like as below. If there are no records for any specific segment (len=0), then we need not create sheet for that segment
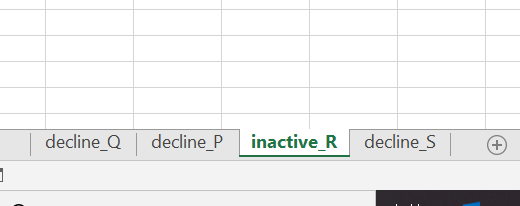
>Solution :
I think need loop by all values in DPM_col column with write each manager to separate file with multiple sheets by conditions:
DPM_col = "manager"
SEG_col = "segment"
for manager, data_output in cdf.groupby(DPM_col):
with pd.ExcelWriter(f'{manager}.xlsx', engine='xlsxwriter') as writer:
m1 = data_output['segment'].isin(['Q','P','S'])
m2 = data_output['dumma'] >= data_output['damma']
df = data_output[m1 & m2]
for seg, v in df.groupby('segment'):
v.to_excel(writer, sheet_name=f"POS_decline_{seg}",index=False)
df1 = data_output[~m1]
for seg1, v1 in df1.groupby('segment'):
v1.to_excel(writer, sheet_name=f"silent_inactive_{seg1}",index=False)