My dataset consists out of two columns, PersonID and Request for application(Aanvraag datum). Some PersonIDs occur multiple times because these persons received multiple request on different dates:
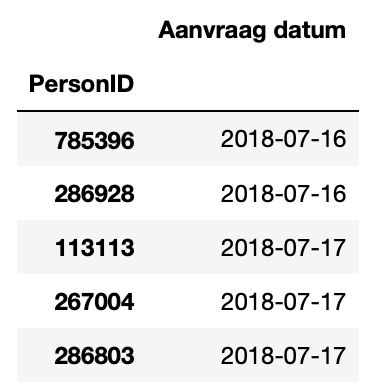
Now I want to create multiple request columns per PersonID. For example if a PersonID occurs three times, then the code creates three columns for three different requests dates. If a PersonID occurs one time, the code assigns NaN to the empty requests. In the end there will be as many columns as the PersonID with the most requests.
Example:
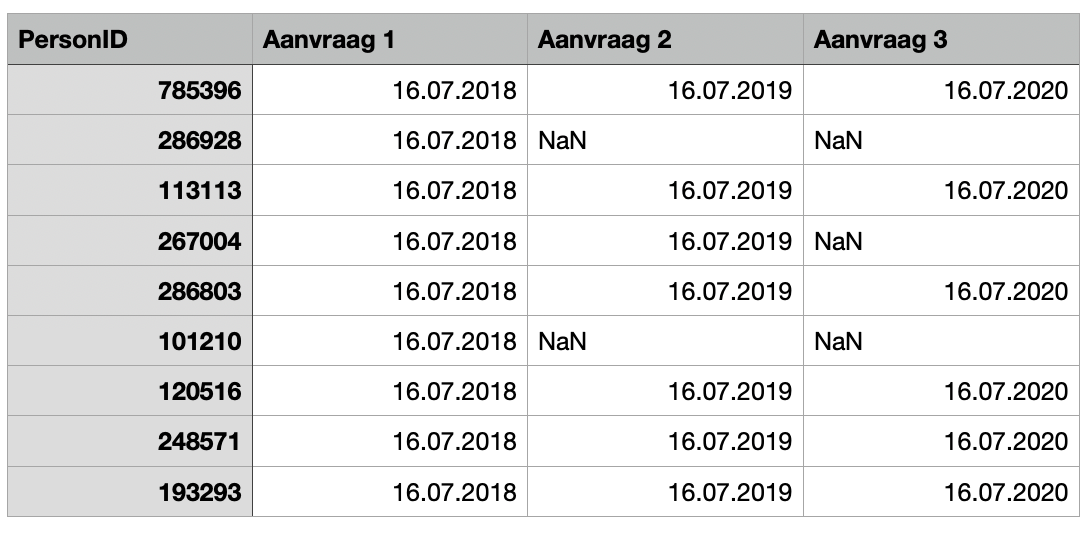
Many thanks!
>Solution :
Use GroupBy.cumcount with DataFrame.set_index and append=True and then Series.unstack with DataFrame.add_prefix:
df1 = (df.set_index(df.groupby(level=0).cumcount().add(1), append=True)['Aanvraag datum']
.unstack()
.add_prefix('Aanvraag '))