Recently I wanted to demonstrate generating a continuous random variable using the universality of the Uniform. For that, I wanted to use the combination of numpy and matplotlib. However, the generated random variable seems a little bit off to me – and I don’t know whether it is caused by the way in which NumPy’s random uniform and vectorized works or if I am doing something fundamentally wrong here.
-
Let U ~ Unif(0, 1) and X = F^-1(U). Then X is a real variable with a CDF F (please note that the F^-1 here denotes the quantile function, I also omit the second part of the universality because it will not be necessary).
-
Let’s assume that the CDF of interest to me is:
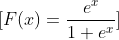
then:
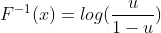
- According to the universality of the uniform, to generate a real variable, it is enough to plug U ~ Unif(0, 1) in the F-1. Therefore, I’ve written a very simple code snippet for that:
U = np.random.uniform(0, 1, 1000000)
def logistic(u):
x = np.log(u / (1 - u))
return x
logistic_transform = np.vectorize(logistic)
X = logistic_transform(U)
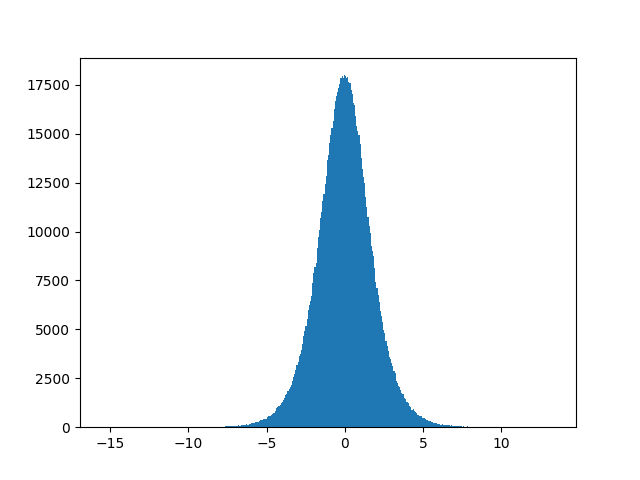
However, the result seems a little bit off to me – although the histogram of a generated real variable X resembles a logistic distribution (which simplified CDF I’ve used) – the r.v. seems to be distributed in a very unequal way – and I can’t wrap my head around exactly why it is so. I would be grateful for any suggestions on that. Below are the histograms of U and X.
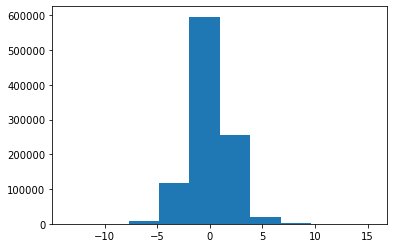
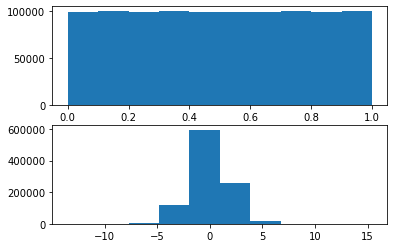
>Solution :
You have a large sample size, so you can increase the number of bins in your histogram and still get a good number samples per bin. If you are using matplotlib‘s hist function, try (for exampe) bins=400. I get this plot, which has the symmetry that I think you expected:
Also–and this is not relevant to the question–your function logistic will handle a NumPy array without wrapping it with vectorize, so you can save a few CPU cycles by writing X = logistic(U). And you can save a few lines of code by using scipy.special.logit instead of implementing it yourself.