So, I’ve been looking into the following code
# Define the model
model = tf.keras.models.Sequential([
# Add convolutions and max pooling
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
# Add the same layers as before
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
# Print the model summary
model.summary()
# Use same settings
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# Train the model
print(f'\nMODEL TRAINING:')
model.fit(training_images, training_labels, epochs=5)
# Evaluate on the test set
print(f'\nMODEL EVALUATION:')
test_loss = model.evaluate(test_images, test_labels)
From what I understand, Convo2D is used to convolute the 26×26 matrix into 32 smaller matrices. This means each matrice will have lost a lot of data. Then we use MaxPooling2D(2, 2). This method further causes data loss. Converting 2×2 matrix to 1×1. That’s another 25% data loss. Again, we repeat this process losing even more data.
Which is further proven by this graph
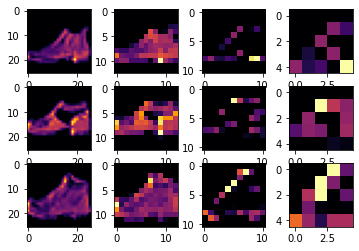
So, Intuition says, Since there are less data pieces available. This means classification would be inaccurate. Just like when your vision blurs, you can’t correctly identify the object.
But surprisingly, the accuracy here goes up.
Can anyone help me figure out why?
>Solution :
The loss of information is a by-product of mapping the image onto a lower dimensional target (compressing the representation in a lossy fashion), which is actually what you want. The relevant information content however is preserved as much as possible, while reducing the irrelevant or redundant information. The initial ‘bias’ of the pooling operation (to assume that close-by patterns can be summarized with such an operation) and the learned convolution kernel set do so effectively.