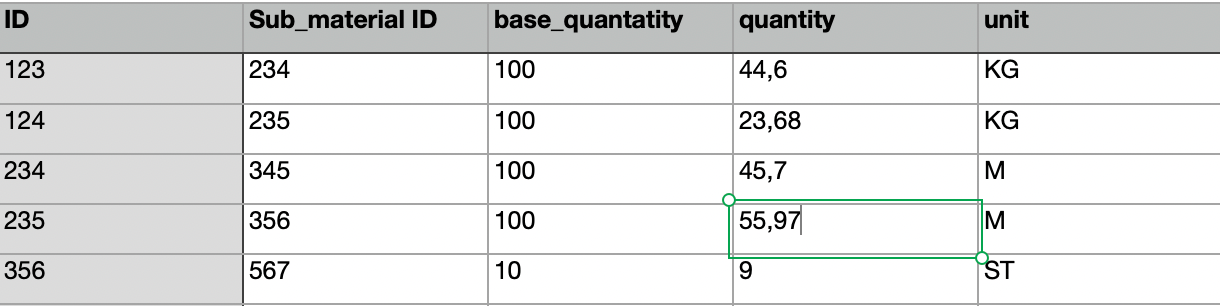
how can I read entries in SQL where the column entries build on each other.
In the first column is the material number. These again consist of different materials, with their own material number in the first column.
How can I find out e.g. from material 123 the quantity of all sub-materials.
I have loaded the data from an Exeltabbele into a Panda database and then loaded this into a SQL database.
Should I use loops in python, to iterate over the table? Or is there a smarter way?
>Solution :
To find out the quantity of all sub-materials for a given material, you can use a self-join in your SQL query. A self-join allows you to join a table to itself, using the same table twice with different aliases.
Here is an example of how you can use a self-join to find the quantity of all sub-materials for material 123:
SELECT t1.material_number, t2.sub_material_number, t2.quantity
FROM your_table t1
JOIN your_table t2 ON t1.material_number = t2.sub_material_number
WHERE t1.material_number = 123
This query will return a result set with three columns: the material number, the sub-material number, and the quantity of the sub-material. The material number will always be 123, since that is what you are filtering for in the WHERE clause. The sub-material number and quantity columns will contain the sub-material information for material 123.
You can also use a loop in Python to achieve the same result. You would need to iterate over the rows in your table, checking if the material number in each row is equal to 123. If it is, you can add the quantity of the sub-material to a running total. This approach might be a little more cumbersome, but it can still work if you prefer to use Python.