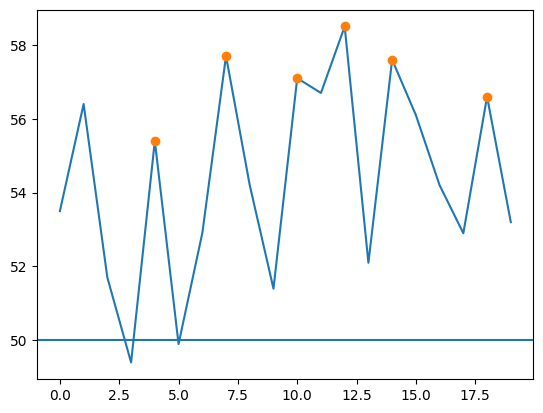
I have data that resembles this:
import pandas as pd
import random
random.seed(901)
rand_list= []
for i in range(20):
x = random.randint(480,600)
rand_list.append(x/10)
df = pd.DataFrame({'INDEX':rand_list})
df['INDEX_DIFF'] = df.INDEX.diff()
df
INDEX INDEX_DIFF
0 53.5 NaN
1 56.4 2.9
2 51.7 -4.7
3 49.4 -2.3
4 55.4 6.0
5 49.9 -5.5
6 52.9 3.0
7 57.7 4.8
8 54.2 -3.5
9 51.4 -2.8
10 57.1 5.7
11 56.7 -0.4
12 58.5 1.8
13 52.1 -6.4
14 57.6 5.5
15 56.1 -1.5
16 54.2 -1.9
17 52.9 -1.3
18 56.6 3.7
19 53.2 -3.4
I want to identify instances where the INDEX value crosses 50 from below and keeps growing while above 50. The first instance when INDEX_DIFF shows -ve indicates that the INDEX has peaked above 50.
For instance, the 6th value 49.9 crosses 50 and continues to grow (52.9, 57.7) before peaking at 57.7 and dropping to 54.2 in the next instance. The INDEX_DIFF gives the first negative value since crossing 50 from below.
How to check this condition and label this as a Peak in a new column in the pandas dataframe?
I have tried to use Last occurrence of a condition but don’t know how to check this elaborate condition.
>Solution :
You could use masks to identify the chunks above 50 (and that started below 50), then get the groupby.idxmax:
m1 = df['INDEX'].shift().lt(50)
m2 = df['INDEX'].gt(50)
group = (m1 & m2).cumsum()
maxima = df[group>0].groupby(group)['INDEX'].idxmax().tolist()
# [4, 12]
df.loc[maxima, 'peak'] = 'X'
Output:
INDEX INDEX_DIFF peak
0 53.5 NaN NaN
1 56.4 2.9 NaN
2 51.7 -4.7 NaN
3 49.4 -2.3 NaN
4 55.4 6.0 X
5 49.9 -5.5 NaN
6 52.9 3.0 NaN
7 57.7 4.8 NaN
8 54.2 -3.5 NaN
9 51.4 -2.8 NaN
10 57.1 5.7 NaN
11 56.7 -0.4 NaN
12 58.5 1.8 X
13 52.1 -6.4 NaN
14 57.6 5.5 NaN
15 56.1 -1.5 NaN
16 54.2 -1.9 NaN
17 52.9 -1.3 NaN
18 56.6 3.7 NaN
19 53.2 -3.4 NaN
If you want all peaks (not just the largest one):
m1 = df['INDEX'].shift().lt(50)
m2 = df['INDEX'].gt(50)
m3 = (m1 & m2).cummax()
peak = df['INDEX'].diff().gt(0) & df['INDEX'].diff(-1).gt(0)
df['peak'] = np.where(m3 & peak, 'X', '')
Output:
INDEX INDEX_DIFF peak
0 53.5 NaN
1 56.4 2.9
2 51.7 -4.7
3 49.4 -2.3
4 55.4 6.0 X
5 49.9 -5.5
6 52.9 3.0
7 57.7 4.8 X
8 54.2 -3.5
9 51.4 -2.8
10 57.1 5.7 X
11 56.7 -0.4
12 58.5 1.8 X
13 52.1 -6.4
14 57.6 5.5 X
15 56.1 -1.5
16 54.2 -1.9
17 52.9 -1.3
18 56.6 3.7 X
19 53.2 -3.4
Graph approach 1:
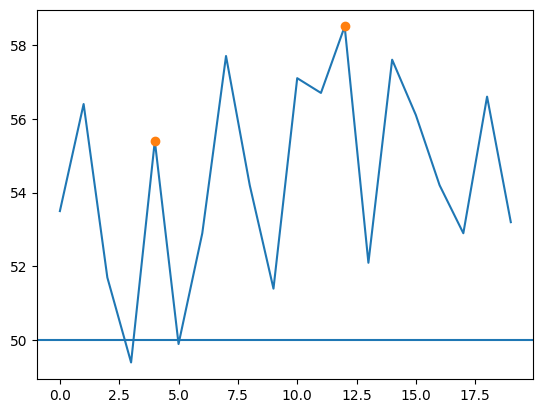
Graph approach 2: