I’m looking for a single pattern to match, free-standing collections of non-Unicode alpha numeric characters. I will eventually do a replace with a single space.
Prerequisite
- In regard to alpha characters, the Unicode category
\p{L}is necessary - In regard to numeric
\dis adequate - white space is included
Match Examples
‘/’ denotes any non-unicode alpha numeric character
aàa 111 /
^ ^^
aàa / 111
^^^
aàa /// 111
^^^^^
aàa/// 111
^^^^
aàa ///111
^^^^
aàa *&^#* 111
^^^^^^^
)(*)* 111
^^^^^^
à- 1
^^
à -1
^^
Unmatched Examples
aàa///111
aàa-111
aà-/*&^*-a-1-1-1
What I have so far
- The pattern
[^\p{L}\d]will match any non-alpha numeric pattern. - Zero-width negative lookahead / lookbehind with word boundaries gets it closer e.g.
(?<!\b)[^\p{L}\d](?!\b)
However, a pattern that solves all the above examples has been elusive
Note: my spidey senses tell me this is likely possible with a single pattern. Though, if this is more efficient or practical as 2 separate patterns, so be it.
>Solution :
\b word boundaries are problematic because those match a boundary between \w and \W, but you’re not using \w and \W.
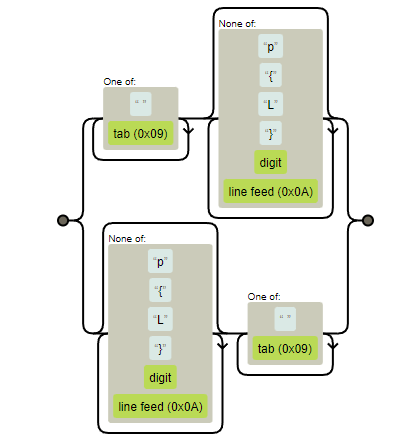
It looks like you always want whitespace on one side or the other of a match so that needs to be worked in. Give this a try. It matches [^\p{L}\d\n]* either preceded or followed by [ \t]+.
[ \t]+[^\p{L}\d\n]*|[^\p{L}\d\n]*[ \t]+
Demo:

Visual Representation