I have a df with "Employee Common Name" and "DisplayName" I would like to NOT select the row if the "Employee Common Name" is within the "DisplayName".
I have not found a way to do that yet but my current (failing) work around is to create a Boolean Column if the "Employee Common Name" is within the "DisplayName".
However everything is false.
Working Example:
import pandas as pd
df = pd.DataFrame({'Employee Common Name': ['Bob', 'Makenzie', 'Alice'],
'DisplayName': ['Robert Inger', 'Kenzie Doe', 'Alice Cooper']})
df['Allowed']=df.apply(lambda x: str(df['Employee Common Name']) in str(df['DisplayName']).lower(), axis=1)
Expected Output:
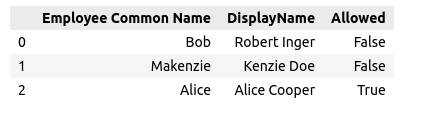
| Employee Common Name | DisplayName | Allowed |
|---|---|---|
| Bob | Robert Inger | False |
| Makenzie | Kenzie Doe | False |
| Alice | Alice Cooper | True |
I already used str.strip() on ‘Employee Common Name"
>Solution :
You did good work, there is a tiny mistake. You never used x (the argument of your lambda function). Use x to access the current row instead of df (accessing the whole series).
Also, as pointed out in other answers and comment, you need to apply .lower() to either to both strings or to none of them.
import pandas as pd
df = pd.DataFrame({'Employee Common Name': ['Bob', 'Makenzie', 'Alice'],
'DisplayName': ['Robert Inger', 'Kenzie Doe', 'Alice Cooper']})
df['Allowed'] = df.apply(
lambda x: x['Employee Common Name'].lower() in x['DisplayName'].lower(), axis=1
)
output as expected