apologies if this sounds like a dumb question, I haven’t worked on Pandas for a long time.
I’ve two data frames, Nodes:

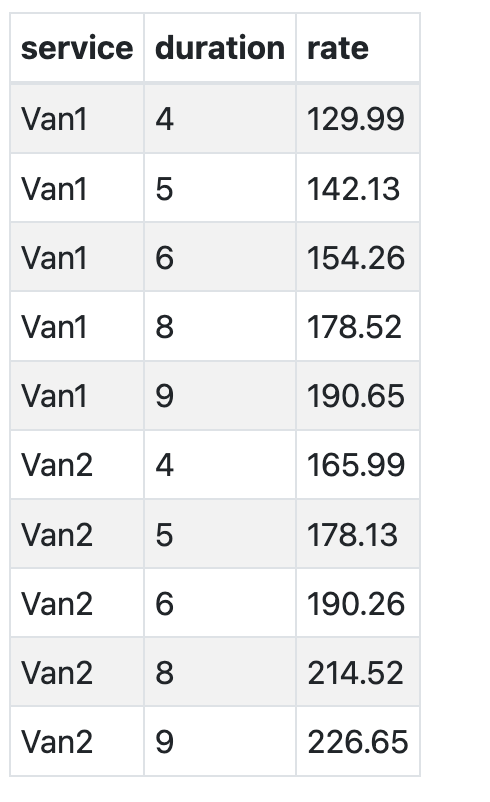
Rate Card:
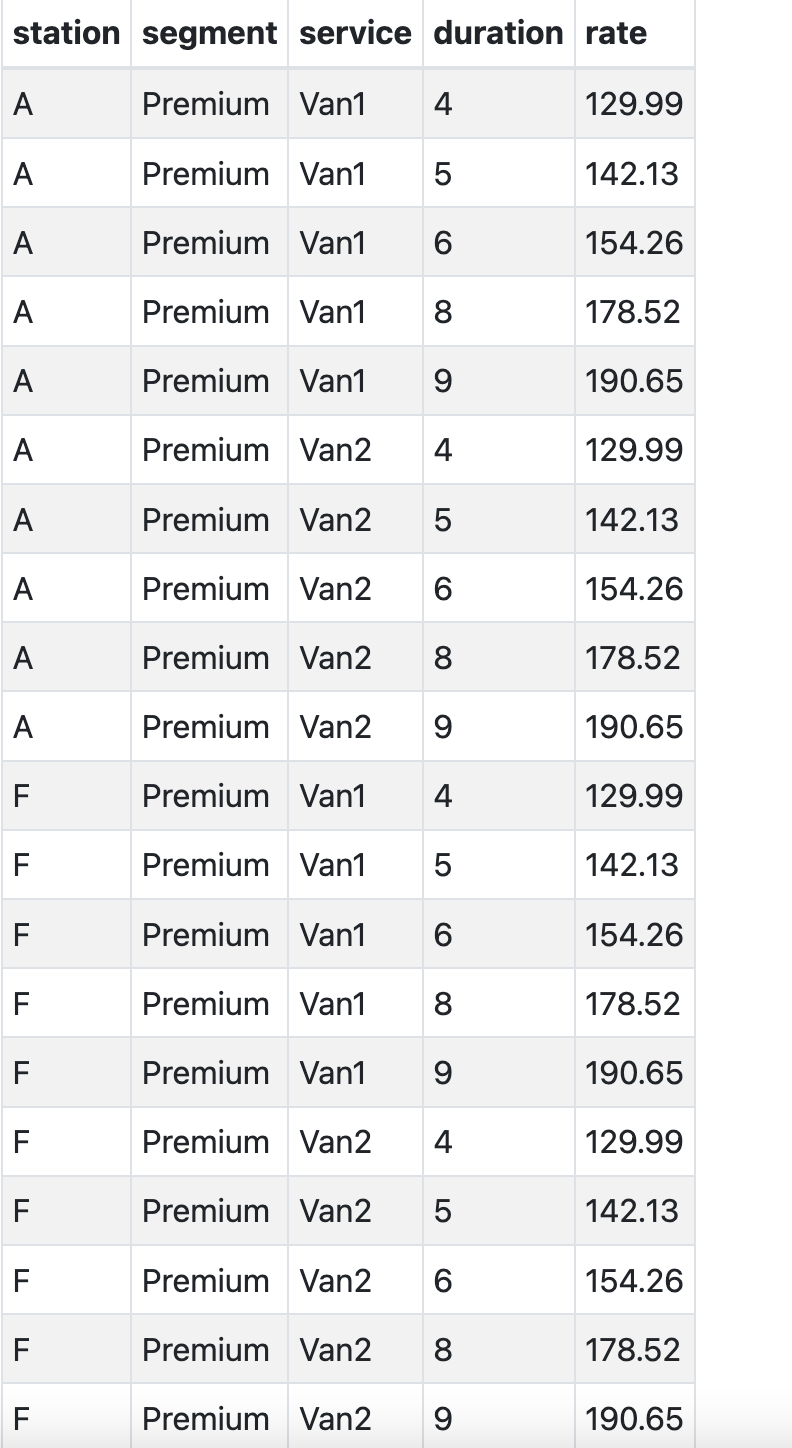
I want the final output to look like this, total would be 7*10= 70 rows:
In R, I use the following piece of code to do this:
prem_subset = merge(nodes, subset(rate_card, select=c("service", "duration","rate")),all=TRUE)
where I'm only selecting some columns from my original rate_card df
I can’t find the Pandas equivalent for this.
>Solution :
IIUC I believe you are looking for pandas merge with option how=cross:
select_cols = ['service', 'duration', 'rate']
nodes.merge(rate_card[select_cols], how='cross')