I work with a spark Dataframe and I try to create a new table with aggregation using groupby :
My data example :

and this is the desired result :
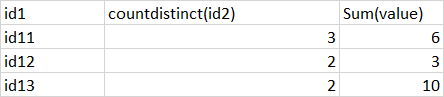
I tried this code data.groupBy("id1").agg(countDistinct("id2").alias("id2"), sum("value").alias("value"))
Anyone can help please ? Thank you
>Solution :
Try using below code –
from pyspark.sql.functions import *
df = spark.createDataFrame([('id11', 'id21', 1), ('id11', 'id22', 2), ('id11', 'id23', 3), ('id12', 'id21', 2), ('id12', 'id23', 1), ('id13', 'id23', 2), ('id13', 'id21', 8)], ["id1", "id2","value"])
Aggregated Data –
df.groupBy("id1").agg(count("id2"),sum("value")).show()
Output –
+----+----------+----------+
| id1|count(id2)|sum(value)|
+----+----------+----------+
|id11| 3| 6|
|id12| 2| 3|
|id13| 2| 10|
+----+----------+----------+