I have a data-frame in which I am trying to remove duplicates using group-by.
data = {
'Type': ['A', 'B', 'B', 'B', 'B', 'B', 'B', 'C', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'C','D','D'],
'Key': ['ZPOC', 'adr#', 'name#', 'city#', 'adr#', 'city#', 'city#', 'ZZRE', 'ZPOC', 'adr#', 'name#', 'city#', 'adr#', 'city#', 'city#', 'ZZRE','item','item']
}
df = pd.DataFrame(data)
In the Type column you can see the row starts from ‘A’. So until next ‘A’ occurs it is my one group. From this group i want to remove duplicate rows by keeping the last occurance, based on values in Key column.
So consider the 1st group only (A-B-B-B-B-B-B-C). In this group adr# and city# is repeating twice so I want to keep the last occurance only from this duplicates. This process shall continue for every group.
Note the duplicate rows should be removed only where Type = ‘B’
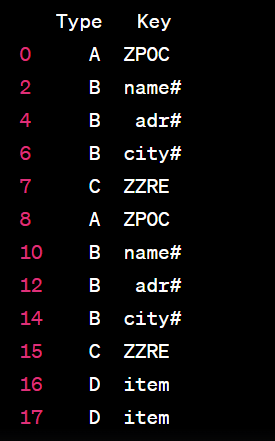
Desired Output
I almost got my desired output but the filtering is not working on Type = ‘B’
import pandas as pd
data = {
'Type': ['A', 'B', 'B', 'B', 'B', 'B', 'B', 'C', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'C','D','D'],
'Key': ['ZPOC', 'adr#', 'name#', 'city#', 'adr#', 'city#', 'city#', 'ZZRE', 'ZPOC', 'adr#', 'name#', 'city#', 'adr#', 'city#', 'city#', 'ZZRE','item','item']
}
df = pd.DataFrame(data)
# Create a mask for rows where 'Type' is 'A'
mask_a = df['Type'] == 'A'
# Create a new column 'Group' to identify the groups based on occurrences of 'A' in 'Type' column
df['Group'] = mask_a.cumsum()
# Filter and remove duplicates within each group
df = df.groupby('Group').apply(lambda x: x.drop_duplicates(subset='Key', keep='last') if (x['Type'] == 'B').any() else x)
# Drop the 'Group' column as it's no longer needed
df.drop('Group', axis=1, inplace=True)
df
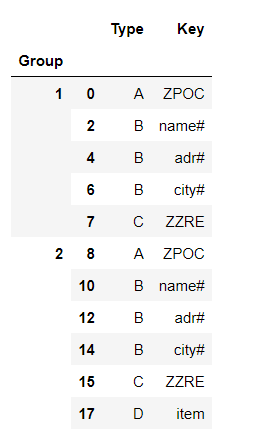
as you can see the duplicate rows where Type = ‘D’ has also been dropped which is suppose to be retained. Somehow I don’t know why the filtering is not working.
>Solution :
You can double .groupby + .drop_duplicates:
out = df.groupby(df["Type"].eq("A").cumsum()).apply(
lambda x: x.groupby("Type", group_keys=False).apply(
lambda x: x.drop_duplicates(keep="last") if x["Type"].iat[0] == "B" else x
)
)
print(out)
Prints:
Type Key
Type
1 0 A ZPOC
2 B name#
4 B adr#
6 B city#
7 C ZZRE
2 8 A ZPOC
10 B name#
12 B adr#
14 B city#
15 C ZZRE
16 D item
17 D item