I have vector of index, that I’d like to filter by. In each column a different row will be selected. The output will be one vector of filtered values with the length of the number of columns. Bud without using the slow cycle. For example
set.seed(123)
(M <- matrix(rnorm(25), 5))
[,1] [,2] [,3] [,4] [,5]
[1,] -0.56047565 1.7150650 1.2240818 1.7869131 -1.0678237
[2,] -0.23017749 0.4609162 0.3598138 0.4978505 -0.2179749
[3,] 1.55870831 -1.2650612 0.4007715 -1.9666172 -1.0260044
[4,] 0.07050839 -0.6868529 0.1106827 0.7013559 -0.7288912
[5,] 0.12928774 -0.4456620 -0.5558411 -0.4727914 -0.6250393
indíces <- c(2, 3, 1, 4, 4)
vect <- c()
for(i in 1:5) {
vect <- c(vect, M[indíces[i], i])
}
vect
[1] -0.2301775 -1.2650612 1.2240818 0.7013559 -0.7288912
I have larger data set and for cycle isn’t therefore ideal. But I couldn’t think of anything better, or find anything better.
>Solution :
We can use a vectorized operation using cbind: M[cbind(indices, 1:ncol(M))]
set.seed(123)
(M <- matrix(rnorm(25), 5))
indices <- c(2, 3, 1, 4, 4)
# vectorized
vect1 <- M[cbind(indices, 1:ncol(M))]
# loop
vect <- c()
for(i in 1:5) {
vect <- c(vect, M[indíces[i], i])
}
# benchmark
library(microbenchmark)
mbm = microbenchmark(
vectorized = M[cbind(indices, 1:ncol(M))],
loop = for(i in 1:5) {
vect <- c(vect, M[indíces[i], i])
},
times=50
)
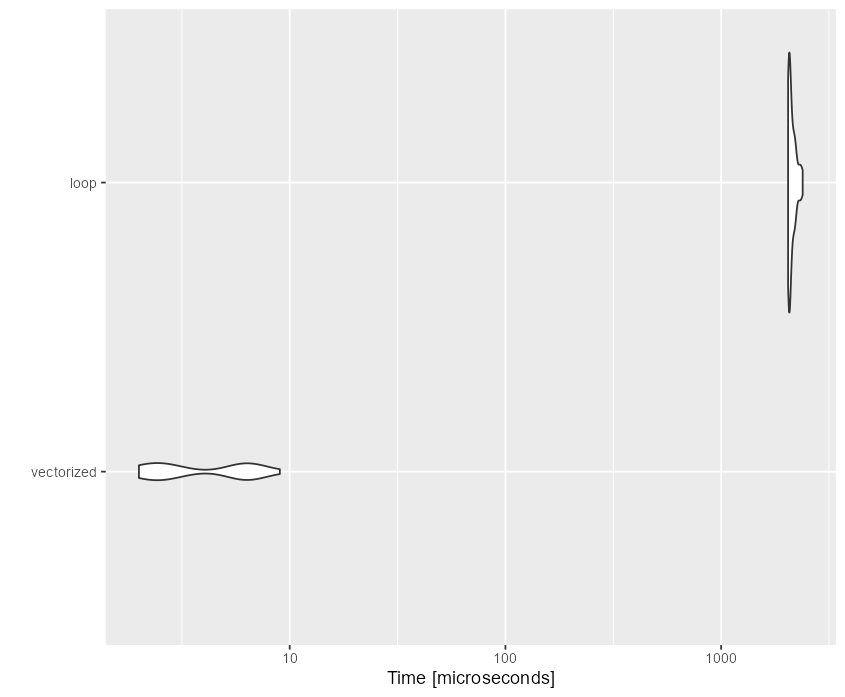
mbm
Unit: microseconds
expr min lq mean median uq max neval cld
vectorized 2.1 2.8 5.158 6.30 6.5 15.6 50 a
loop 2062.8 2089.2 2143.418 2114.55 2183.8 2391.0 50 b
autoplot(mbm)