I have this table t1 in databrick as below
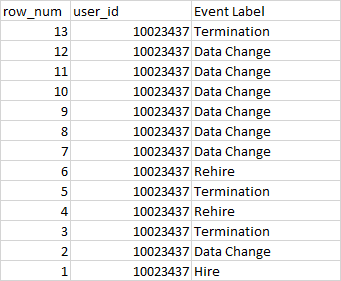
Can help me to write a query to get this result:

sort the table data by row_num by descending first, then look at "Event Label" column, if "Event Label" is "Hire" then Result is 0, the result is 0 for the next rows until encountering the "Event label" as "Rehire", then the result is increased by 1 to be 1, and 1 for the following rows until encountering the "Event label" as "Rehire", then the result is increased by 1 again to be 2, and so on, repeating the same process.
I tried some way but no luck.
>Solution :
In pure SQL, a cumulative sum would be sufficient…
SELECT
*,
SUM(
CASE WHEN [event label] = 'Rehire' THEN 1 ELSE 0 END
)
OVER (
PARTITION BY user_id
ORDER BY row_id
)
AS Result
FROM
t1