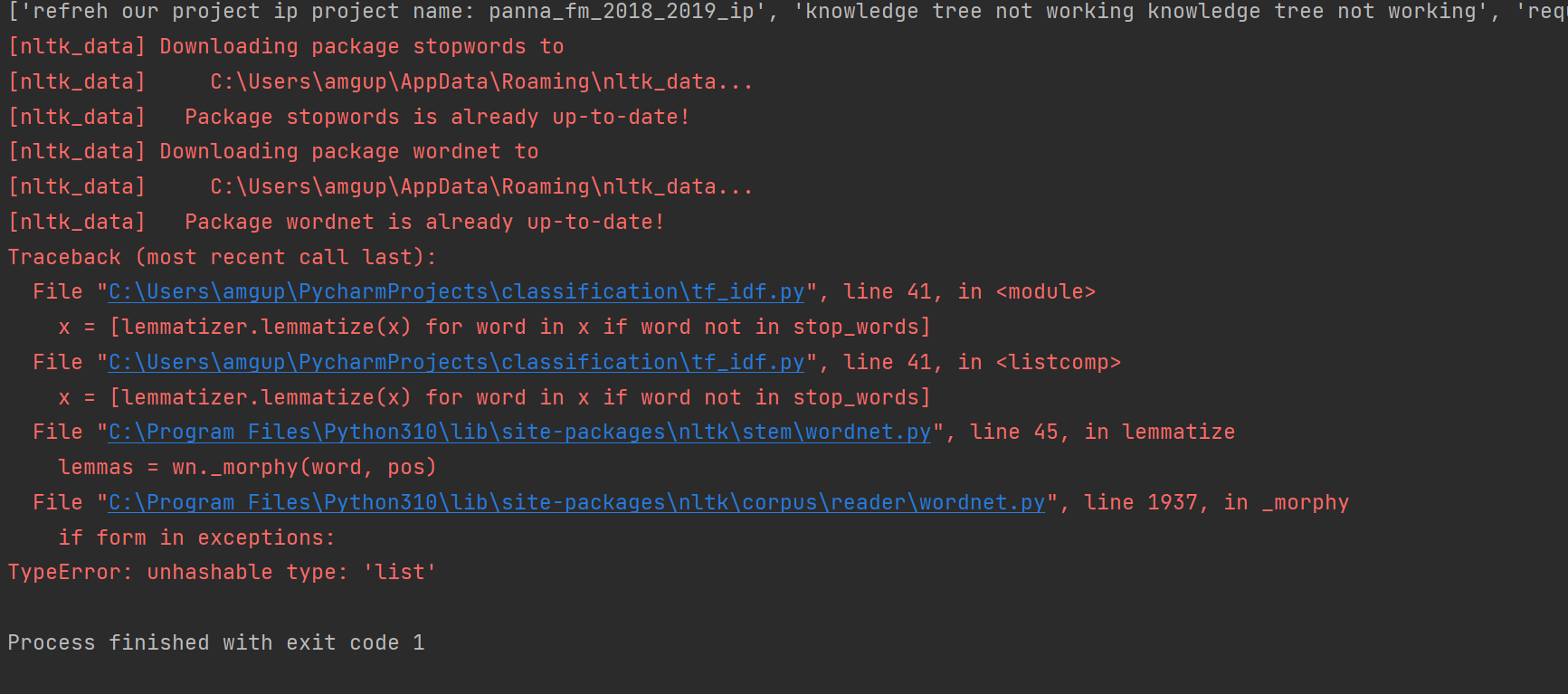
This is the code that I’m running on PyCharm and keep getting an error saying if form in exceptions:
TypeError: unhashable type: ‘list’. I am new to python. Kindly help me out
import matplotlib.pyplot as plt
import pandas as pd
import nltk
data=pd.read_excel(r"C:\Users\amgup\Downloads\classification\Model_Dataset.xlsx", usecols=['Category','Title','Description'])
# Combining title and description into one column
data['combined']= (data['Title']+' '+data['Description']).str.lower()
data=data.drop(columns=['Title','Description'])
print(data)
# shuffling the order of the rows. sample() returns random rows from the data and frac specifies what fraction has to be returned
# frac=1 means the entire data in a random order
data=data.sample(frac=1)
print(data)
# Counting the numnber of times each category has appeared
count=data['Category'].value_counts()
print(count)
# Creating a barplot of the count
bar_plot=plt.barh(count.keys(),count.values)
plt.savefig(r"C:\Users\amgup\Downloads\classification\barplot_of_categories.png")
y=list(data['combined'])
print(y)
#lemmatization
from nltk.corpus import stopwords
nltk.download('stopwords')
stop_words = set(stopwords.words('english'))
tokens=[]
from nltk.stem import WordNetLemmatizer
nltk.download('wordnet')
lemmatizer = WordNetLemmatizer()
for x in y:
x = str(x)
x = x.lower()
x = x.split()
x = [lemmatizer.lemmatize(x) for word in x if word not in stop_words]
x = ' '.join(x)
tokens.append(x)
print(tokens)
>Solution :
x = x.split() turns your string x into the list.
In your comprehension, you should put lemmatizer.lemmatize(word) instead of lemmatize(x)
You are looping through the words in x x and you want to do transformation on each word