I am trying to apply my own function. Below you can see the data and function.
import pandas as pd
import numpy as np
data_test = {
'sales_2017': [100,0,300,0,200],
'profit_2017': [20,0,30,50,0],
}
df = pd.DataFrame(data_test, columns = ['sales_2017','profit_2017','sales_2018','profit_2018'])
df['effective']= df['profit_2017']/df['sales_2017']
df
# Create distribution table
conditions = [
(df['effective'] == 0),
(df['effective'] > 0.1) & (df['effective'] < 0.20),
(df['effective'] > 0.20),
(df['effective'] == "NaN"),
(df['effective'] == "inf"),
]
values = ['Equal to zero','Between 0.1 and 0.2', 'Above 0.2', 'Equal to NaN', "Equal to infinity"]
df['effective_range'] = np.select(conditions, values)
distribution_table = df.groupby('effective_range').agg(count=('effective_range','count'))
So main idea here is to create a distribution table in accordance with this condtions ‘Equal to zero’,’Between 0.1 and 0.2′, ‘Above 0.2’, ‘Equal to NaN’, "Equal to infinity".
My set have values with 'Nan' and also with 'inf' and this causes a problem with final table and below you can see pic.
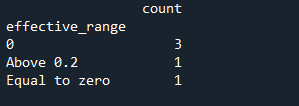
So can anybody help me how to solve this problem and to have a table like a table below?
effective_range count
Equal to zero 1
Between 0.1 and 0.2 0
Above 0.2 1
Equal to NaN 1
Equal to infinity 1
>Solution :
Use Series.isna and numpy.isinf methods:
# Create distribution table
conditions = [
(df['effective'] == 0),
(df['effective'] > 0.1) & (df['effective'] < 0.20),
(df['effective'] > 0.20),
(df['effective'].isna()),
(np.isinf(df['effective'])),
]
values = ['Equal to zero','Between 0.1 and 0.2', 'Above 0.2',
'Equal to NaN', "Equal to infinity"]
df['effective_range'] = np.select(conditions, values)
distribution_table = df.groupby('effective_range').agg(count=('effective_range','count'))
print (distribution_table)
count
effective_range
0 2
Above 0.2 1
Equal to NaN 1
Equal to zero 1