I am facing an odd issue where my lookup is returning a filenotfound error when I use a wildcard path. If I specify and exact file path, the lookup runs without error. However, if I replace the filename with a *, I get a filenotfound error.
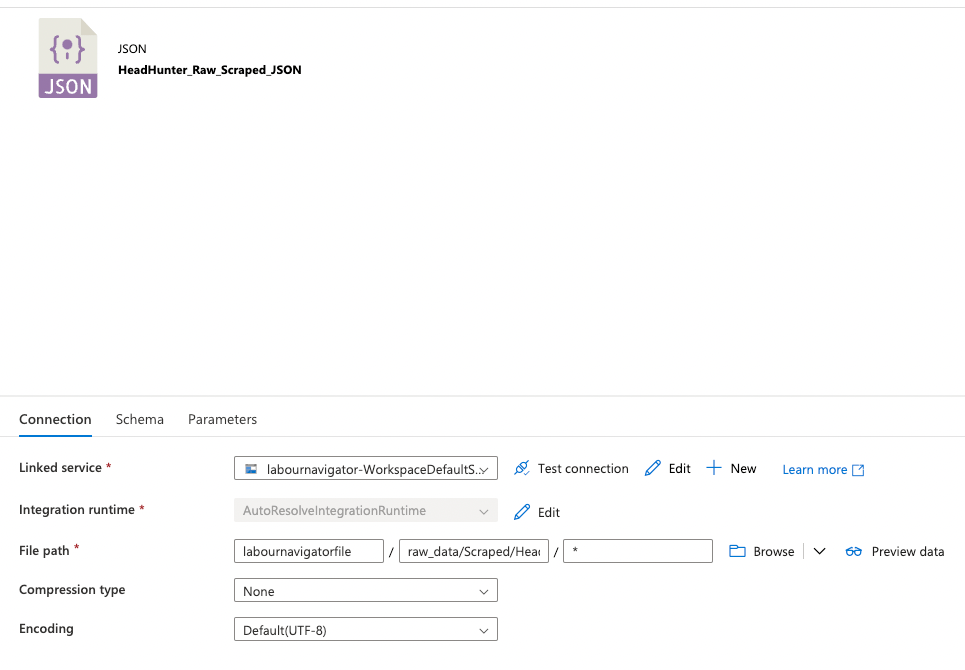
The file is Data_643.json, located in my Azure Data Lake Storage Gen2, under the labournavigatorfile system. The exact file path is:
labournavigatorfile/raw_data/Scraped/HeadHunter/Saudi_Arabia/Data_643.json.
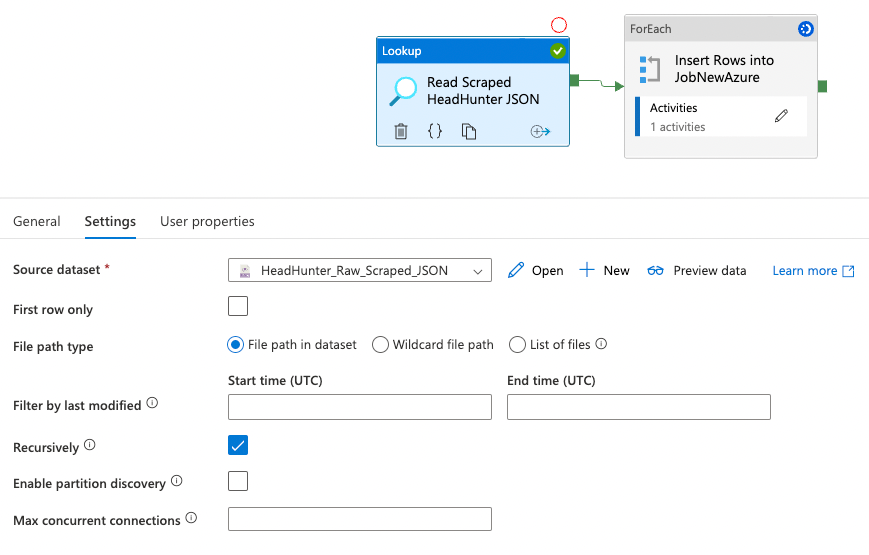
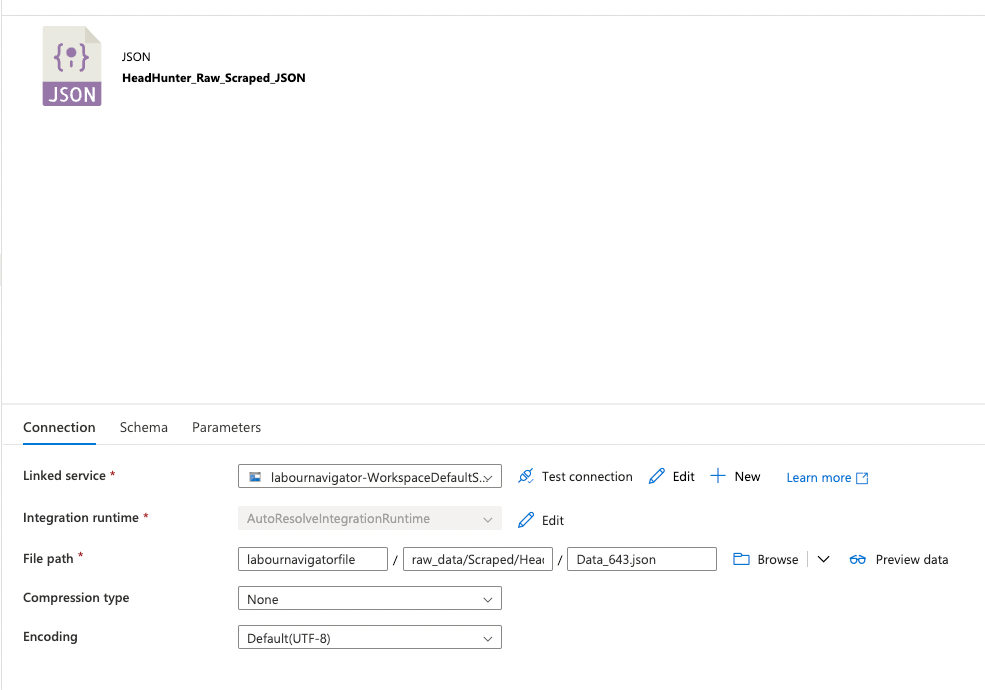
If I put this exact path into the Integration dataset configuration, the pipeline runs without issue. However, as soon as I replace the ‘Data_643.json’ with a ‘*’, the pipeline crashes with a filenotfound error.
What am I doing wrong? Many Thanks for any support. This must be something very simple that I am missing.
Exact path works:
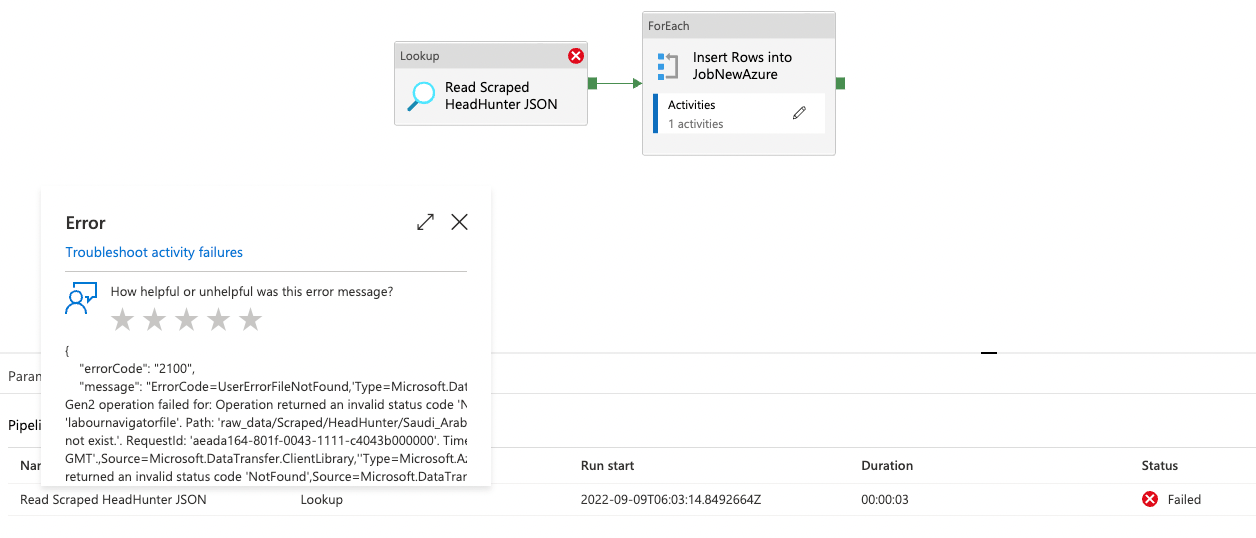
Wildcrad path throws error:
>Solution :
I have 3 files in my container as file1.json, file2.json, file3.json as shown below:

The following is how I configured my dataset to read using wildcard with configuration same as in the image provided in the question.

- When I used this in
lookupI got the same error:

- To overcome this, go to your lookup activity. When you want to use wildcards to read a file/files, check the
wildcard file pathoption. Then specify the folder structure and use wildcard where required. The following is an image for reference.

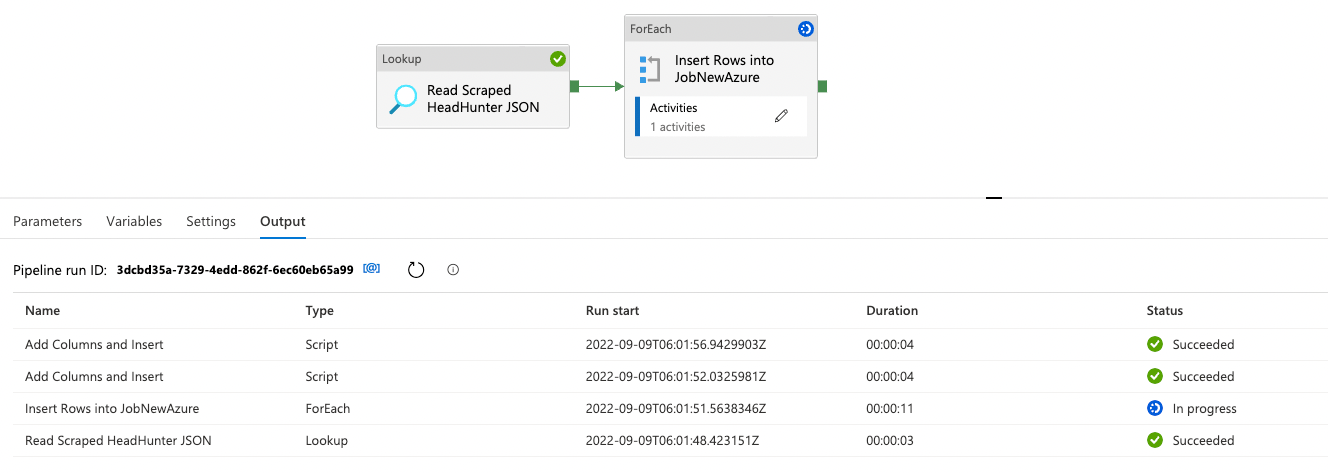
- The following is the debug output when I run the pipeline (Each of my files had 10 rows):
