I am trying to make a program that get the stock symbol from a list on Yahoo Finance. I have tried
changing html5lib to lxml and html.parser. Neither of those worked for me.
The website is: https://finance.yahoo.com/screener/unsaved/f491bcb6-de80-4813-b50e-d6dc8e2f5623?dependentField=sector&dependentValues=Consumer%20Cyclical
There are supposed to be 25 results but if you see by running it we only get about half. (13)
Anyone got any solutions?
import requests
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36', 'Accept' : 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language' : 'en-US,en;q=0.5', 'DNT' : '1', # Do Not Track Request Header 'Connection' : 'close'
}
from bs4 import BeautifulSoup
URL = 'https://finance.yahoo.com/screener/unsaved/f491bcb6-de80-4813-b50e-d6dc8e2f5623?dependentField=sector&dependentValues=Consumer%20Cyclical'
page = requests.get(URL, headers=headers, timeout=5)
soup = BeautifulSoup(page.content, "html5lib")
results = soup.find(id="screener-results")
stock_ = results.find_all("tr", class_="simpTblRow Bgc($hoverBgColor):h BdB Bdbc($seperatorColor) Bdbc($tableBorderBlue):h H(32px) Bgc($lv2BgColor)")
x = 0
for stock_ in stock_:
x = x + 1
stock_symbol = stock_.find('a', class_='Fw(600) C($linkColor)')
print(str(stock_symbol.text.strip()) + '\n' + str(x))
>Solution :
There is an easy fix for this. The table is using alternating colors for each row so one row has the color Bgc($lv2BgColor) and the next one Bgc($lv1BgColor). As you only get those with Bgc($lv2BgColor) you only get half of the results.
Here a screenshot 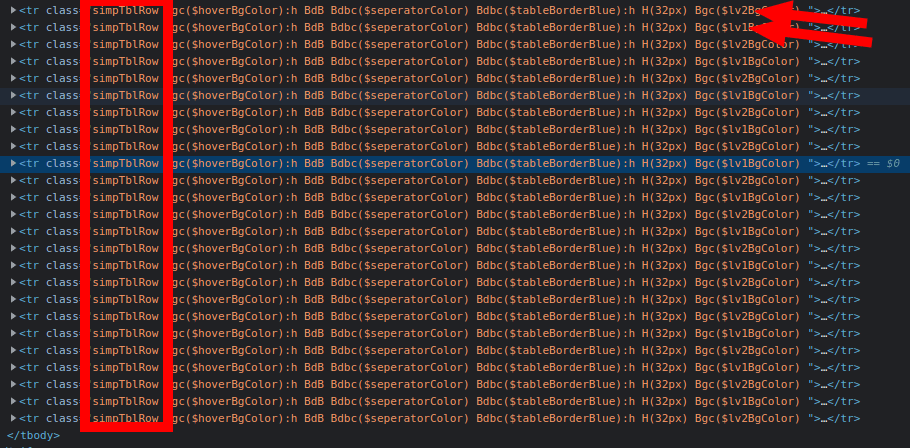 of the relevant HTML of the webpage.
of the relevant HTML of the webpage.
In your case there is actually no need to be so precise with the class, just use class_="simpTblRow" and you should get all results.
By the way: There also is a Yahoo Finance API which is free for up to 100 requests per day so you might be able to use that instead of web scraping the from their web page.