I have made a very simple web scraper which iterates through a list of links and scrapes the text and dates from them and outputs this into a text file.
So far everything has been working fine but I have received an error which only occurs for certain links.
for reference, I am using the same website (Yahoo Finance) which contains the same html for each webpage.
Below is an example of the issue I am running into. The function successfully retrieves the date from the first link, but fails on the second one:
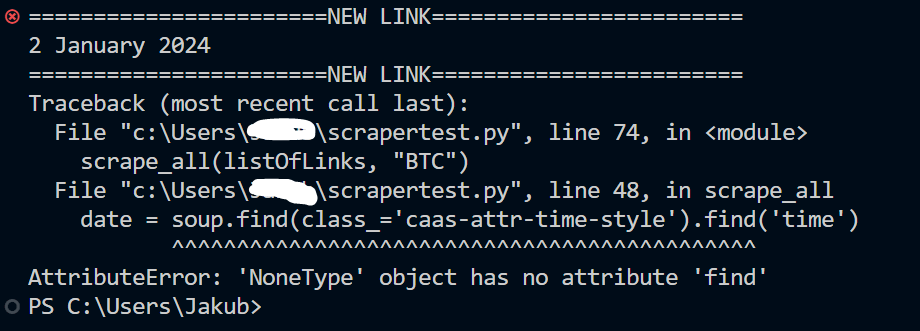
Below is the entire code for the web scraper:
from bs4 import BeautifulSoup
import datetime
import yfinance as yf
def unique_filename () :
current_date = datetime.datetime.now()
day_month_string = current_date.strftime("%S-%M-%H-%d")
filename = day_month_string
filename+="-ScrapedData.txt"
return filename
def get_currency_info (name) :
currency = yf.Ticker(name)
history = currency.history(period="1mo")
return history
def scrape_all (list, curr) :
filename = unique_filename()
with open(filename, 'a') as file:
file.write(get_currency_info(curr).to_string())
file.write("\n\n\n\n")
for link in list :
print("=======================NEW LINK========================")
source = requests.get(link).text
soup = BeautifulSoup(source, 'lxml')
date = soup.find(class_='caas-attr-time-style').find('time')
with open(filename, 'a') as file :
dateToAppend = (date.get_text().split('at'))[0]
print(dateToAppend)
file.write(f"Date: {dateToAppend}")
file.write("\n\n\n\n")
texts = soup.find_all('p')
for text in texts:
#print(text.get_text())
with open(filename, 'a') as file:
text_to_append = text.get_text()
file.write(text_to_append)
file.write("\n")
if __name__ == "__main__" :
listOfLinks = [
'https://uk.finance.yahoo.com/news/bitcoin-byd-bp-marks-spencer-trending-tickers-112621324.html',
'https://uk.yahoo.com/finance/news/bitcoin-rally-fuelled-by-shrinking-supply-102808887.html'
]
scrape_all(listOfLinks, "BTC")
print("=======================LIST END========================")```
>Solution :
EDIT
Based on your comment, the page loads in your browser but not through requests.
You can add the user-agent header to requests.get() to trick the page that you’re not a robot:
HEADERS = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36' }
...
source = requests.get(link, headers=HEADERS).text
...
See also:
Original Answer
I think the error is clear:
`NoneType` object has no attribute 'find'
which means, that in your code:
date = soup.find(class_='caas-attr-time-style').find('time')
the soup.find(class_='caas-attr-time-style') is returning None.
To investigate the problem, I’ve caught the exception and printed out the soup to see what’s going on:
soup = BeautifulSoup(source, 'lxml')
...
try:
date = soup.find(class_='caas-attr-time-style').find('time')
except AttributeError:
print("Attribute Error\n", soup.prettify())
Which clearly Prints:
<body>
<!-- status code : 404 -->
<!-- Not Found on Server -->
<table>
<tbody>
<tr>
<td>
<img alt="Yahoo Logo" src="https://s.yimg.com/rz/p/yahoo_frontpage_en-US_s_f_p_205x58_frontpage.png"/>
<h1 style="margin-top:20px;">
Will be right back...
</h1>
<p id="message-1">
Thank you for your patience.
</p>
<p id="message-2">
Our engineers are working quickly to resolve the issue.
</p>
</td>
</tr>
</tbody>
</table>
</body>
</html>
So, from the above HTML it seems like the page is currently down.
What you can do to solve the problem is to use a Try/Except block and skip over it the value doens’t exist:
for link in list:
print("=======================NEW LINK========================")
source = requests.get(link).text
soup = BeautifulSoup(source, 'lxml')
try:
date = soup.find(class_='caas-attr-time-style').find('time')
except AttributeError:
date = 'No date found'
with open(filename, 'a') as file:
dateToAppend = (date.get_text().split('at'))[0]
print(dateToAppend)
file.write(f"Date: {dateToAppend}")
file.write("\n\n\n\n")