Consider the following dataframe:
import polars as pl
df = pl.DataFrame({
"id": [1, 1, 2, 2, 2],
"sku1": [4, 2, 3, None, 1],
"sku2": [None, 3, None, 3, None],
})
I want to calculate the percentage of each sum per identifier over the total per sku.
So, the end result should like this:
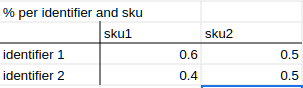
Any ideas? Please note that the number of sku columns might vary over time.
>Solution :
import polars as pl
df = pl.DataFrame({
"id": [f'identifier {x}' for x in [1, 1, 2, 2, 2]],
"sku1": [4, 2, 3, None, 1],
"sku2": [None, 3, None, 3, None],
})
kcols = ['id']
vcols = pl.all().exclude(kcols)
print(df.group_by(kcols).agg(vcols.sum()).with_columns(vcols / vcols.sum()))
shape: (2, 3)
┌──────────────┬──────┬──────┐
│ id ┆ sku1 ┆ sku2 │
│ --- ┆ --- ┆ --- │
│ str ┆ f64 ┆ f64 │
╞══════════════╪══════╪══════╡
│ identifier 1 ┆ 0.6 ┆ 0.5 │
│ identifier 2 ┆ 0.4 ┆ 0.5 │
└──────────────┴──────┴──────┘