I am writing a script to format data from an excel sheet template I frequently use so that I can work with it without having to manually format it each time. I am using the following code to remove some useless header rows that appear and make the third row the actual header.
new_header = df.iloc[2] #grab the third row for the header
df = df[3:] #take the data below the new header row
df.columns = new_header #set the header row as the df header
df.reset_index(drop=True, inplace=True)
This works great except when I view the dataframe there is a 2 above my index. This does not appear to be the index name or a column name (I have checked both) and there does not appear to be multiindexing present. This seems rather simple but I am stumped as to what this 2 is and how I can remove it.
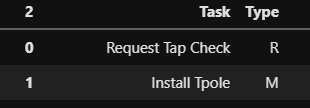
Any help would be appreciated.
>Solution :
Check the result of your new_header when you pull the third row df.iloc[2]. You will notice that it has the index 2 in the output. That is where it comes from. You can git rid of it by changing the first line to new_header = df.iloc[2].to_list()