I would like to scrape all the statistics in the page
https://fantasy.premierleague.com/statistics
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
import numpy as np
options = Options()
options.add_argument("--start-maximized")
import time
start = time.process_time()
time.sleep(3)
s = Service(path)
driver = webdriver.Chrome(options=options, service=s)
#go to page
driver.get('https://fantasy.premierleague.com/statistics')
wait = WebDriverWait(driver, 2)
#accept cookies
try:
wait.until(EC.element_to_be_clickable((By.XPATH, '/html/body/div[2]/div/div/div[1]/div[5]/button[1]'))).click()
except:
pass
list= np.arange(1, 22, 1).tolist()
for i in list:
#extract table on the first page
content = driver.page_source
soup = BeautifulSoup(content, features="html.parser")
table = soup.find_all('table',attrs={'class':'Table-ziussd-1 ElementTable-sc-1v08od9-0 dUELIG OZmJL'})
df = pd.read_html(str(table))[0]
df.drop(columns=df.columns[0], axis=1, inplace=True)
df.to_parquet(f'table_pg_{i}_{date}.parquet.gzip')
pd.read_parquet(f'table_pg_{i}_{date}.parquet.gzip')
#scroll down to get the page data below the first scroll
scrollDown = "window.scrollBy(0,2000);"
driver.execute_script(scrollDown)
#driver.execute_script("window.scrollTo(50, document.body.scrollHeight);")
try:
#click on the next button
wait = WebDriverWait(driver, 2)
wait.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="root"]/div[2]/div/div[1]/div[3]/button[3]/svg'))).click()
except:
pass
print('Execution Time: ', time.process_time() - start)
#check the last table
pd.read_parquet(f'table_pg_{i}_{date}.parquet.gzip')
The code does not return any error message, but the last table scraped should be on page 21,
as in the screenshot below
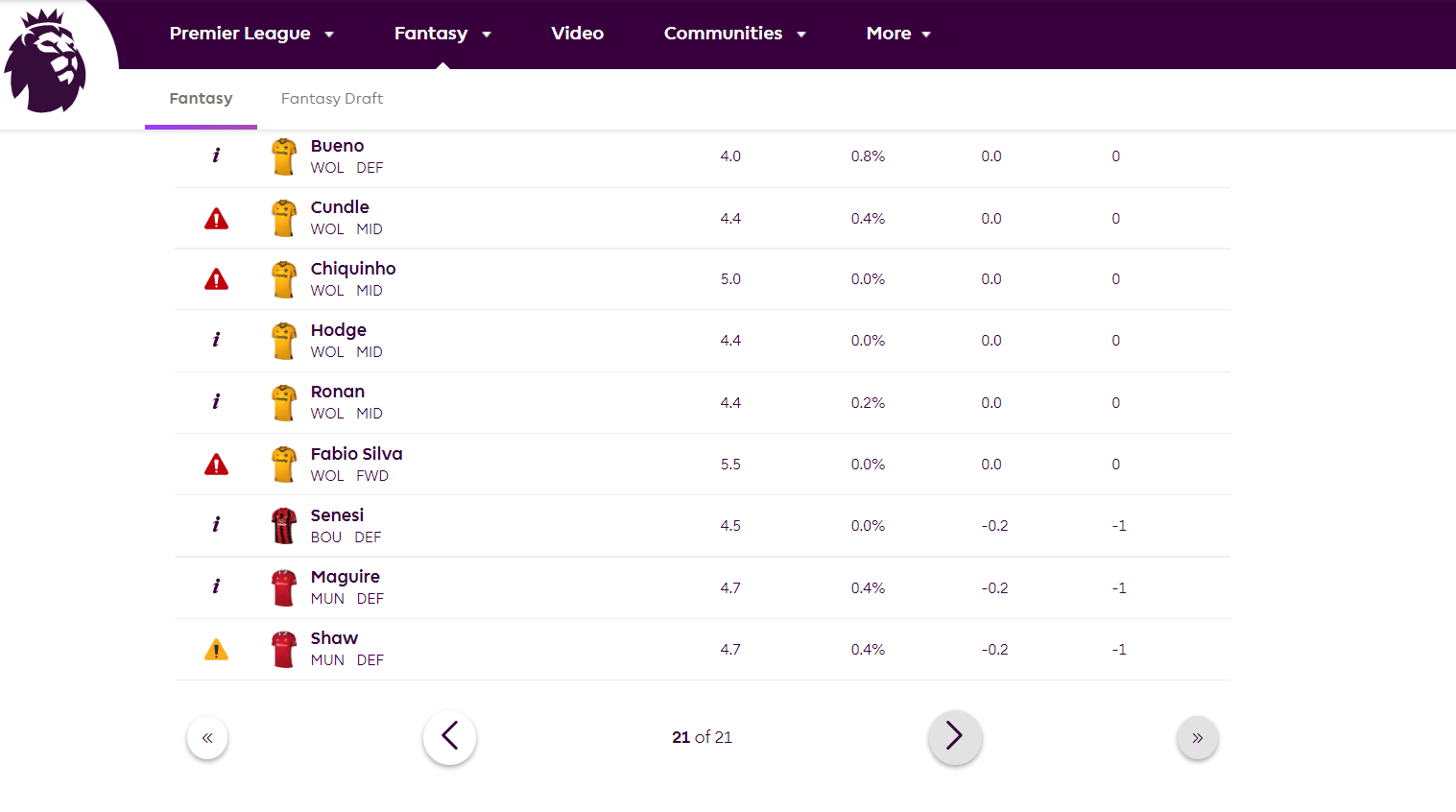
whereas my parquet file returns the results on the first page.
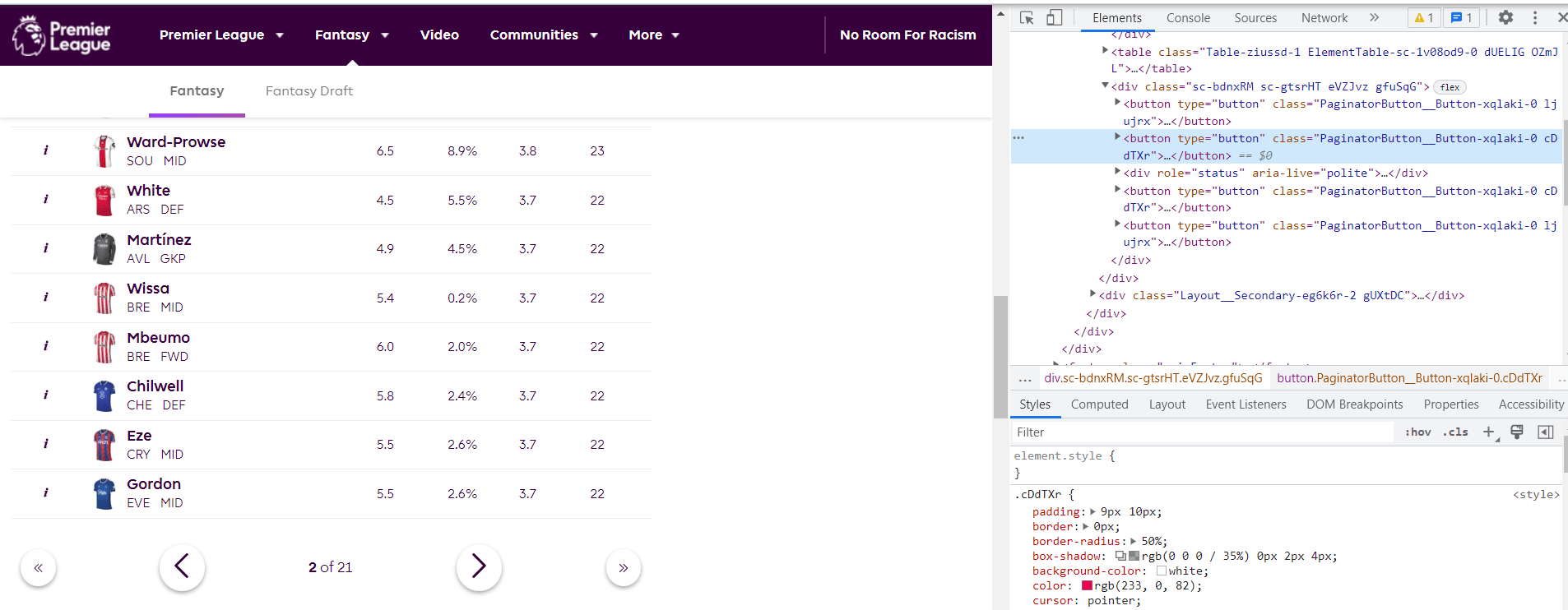
Both the previous and next buttons have the same CSS selectors.
>Solution :
In this command try changing from wait.until(EC.element_to_be_clickable((By.XPATH, '//*[@id="root"]/div[2]/div/div[1]/div[3]/button[3]/svg'))).click() to
wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "button svg[class*='ChevronRight']"))).click()
Also make sure you are scrolling to the bottom so this element becomes clickable