I have loaded Data into a few Spark dataframes with a provided schema into a Jupyter Notebook.
Now I want to add a prefix to the column names of all dataFrames. There are multiple post regarding this topic (e.g. Rename more than one column and the renaming itself does work using the previously mentioned answer code:
df = df.select([f.col(c).alias('z_' + c) for c in df.columns])
However, as soon as I am out of my loop, the changes I made to the column names seem to be forgotten:
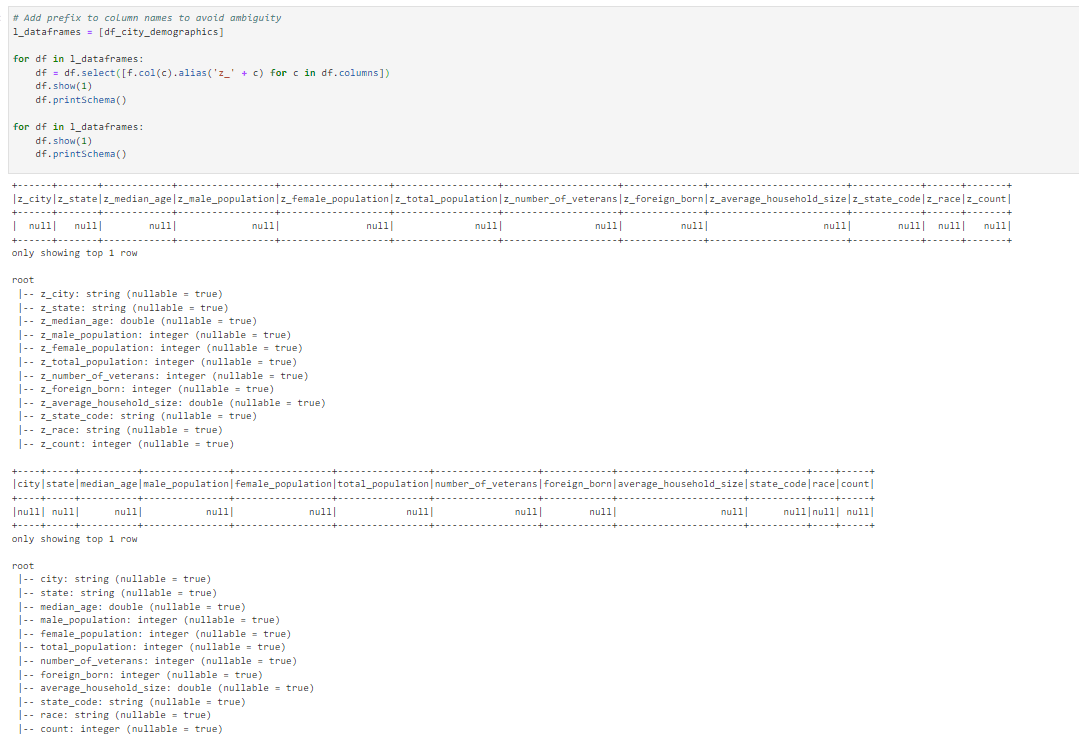
I tried using collect() but that did not help.
I also tried several other column remaining alternatives. But as my problem is rather with the saving of the changes and not the changes itself that also did not work out.
Any suggestions on what I am missing?
>Solution :
Looks like this is an issue with how python references items when iterating over a list, see https://stackoverflow.com/a/55629813
Try using another method,
E.g.
def prefix_cols(df, pref):
return df.select([f.col(c).alias(pref + c) for c in df.columns])
df_list = [prefix_cols(df, 'z_') for df in df_list]