I am trying to see how word frequency correlates with phonotactic probability using R, but there are a few issues. First, and most generally, I don’t know merge these two graphs together (i want them to appear on the same axis).
This leads to a second problem because the first graph’s y values are in probabilities, and the second is a count, so the scales are not the same. Should I combine data frames first, or is there a simpler way to merge two graphs?
Here is the reproducible sample, and the code for my graphs:
Phonotactic_Probability <-structure(list(Word = c("Baby", "Bagel", "Bandage", "Banjo",
"Carriage", "Carrot", "Chicken", "Chipmunk", "City", "Cobra",
"Cocoa", "Fairy", "Ferret", "Garbage", "Garlic", "Letter", "Lettuce",
"Lobster", "Locker", "Marble", "Marker", "Muffin", "Mushroom",
"Pasta", "Peacock", "Peanut", "Possum", "Puppet", "Puppy", "Raccoon",
"Racket", "Rooster", "Ruler", "Sandal", "Sandwich", "Scissors",
"Turkey", "Turtle", "Whistle", "Wizard"), `Biphone Probability...5` = c(0.0029,
0.0023, 0.0274, 0.012, 0.025, 0.02, 0.0048, 0.0019, 0.0029, 0.0057,
4e-04, 2e-04, 0.0085, 0.0209, 0.0199, 0.0061, 0.0044, 0.0168,
0.0014, 0.0222, 0.0202, 0.0033, 0.004, 0.0265, 4e-04, 0.0044,
0.0045, 0.009, 0.0025, 0.0023, 0.0079, 0.0153, 0.0031, 0.0278,
0.0265, 0.008, 0.0042, 0.0107, 0.0163, 0.0064), `Biphone Probability` = c(0.0029,
0.0023, 0.0274, 0.012, 0.025, 0.02, 0.0048, 0.0019, 0.0029, 0.0057,
4e-04, 2e-04, 0.0085, 0.0209, 0.0199, 0.0061, 0.0044, 0.0168,
0.0014, 0.0222, 0.0202, 0.0033, 0.004, 0.0265, 4e-04, 0.0044,
0.0045, 0.009, 0.0025, 0.0023, 0.0079, 0.0153, 0.0031, 0.0278,
0.0265, 0.008, 0.0042, 0.0107, 0.0163, 0.0064)), class = c("grouped_df",
"tbl_df", "tbl", "data.frame"), row.names = c(NA, -40L), groups = structure(list(
Word = c("Baby", "Bagel", "Bandage", "Banjo", "Carriage",
"Carrot", "Chicken", "Chipmunk", "City", "Cobra", "Cocoa",
"Fairy", "Ferret", "Garbage", "Garlic", "Letter", "Lettuce",
"Lobster", "Locker", "Marble", "Marker", "Muffin", "Mushroom",
"Pasta", "Peacock", "Peanut", "Possum", "Puppet", "Puppy",
"Raccoon", "Racket", "Rooster", "Ruler", "Sandal", "Sandwich",
"Scissors", "Turkey", "Turtle", "Whistle", "Wizard"), .rows = structure(list(
1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L, 11L, 12L, 13L,
14L, 15L, 16L, 17L, 18L, 19L, 20L, 21L, 22L, 23L, 24L,
25L, 26L, 27L, 28L, 29L, 30L, 31L, 32L, 33L, 34L, 35L,
36L, 37L, 38L, 39L, 40L), ptype = integer(0), class = c("vctrs_list_of",
"vctrs_vctr", "list"))), class = c("tbl_df", "tbl", "data.frame"
), row.names = c(NA, -40L), .drop = TRUE))
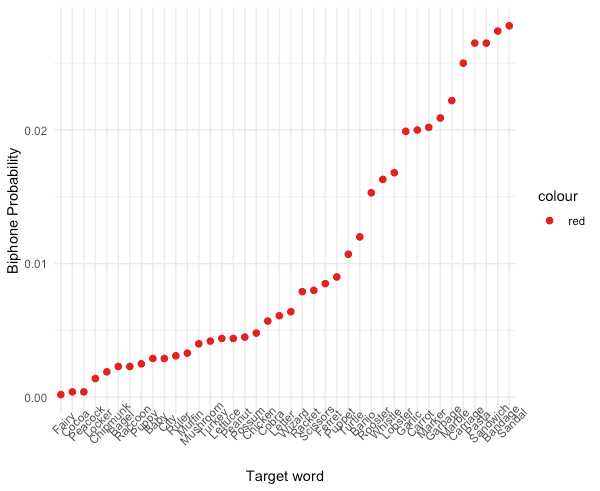
###Phonotactic Plot
Phonotactic_Probability %>%
ggplot(aes(y = `Biphone Probability`, x = reorder(Word,`Biphone Probability`), col = "red")) +
labs(y= "Biphone Probability", x = "Target word")+
geom_point(size = 2)+
theme_minimal() +
theme(axis.text.x = element_text(angle = 45))+
scale_color_brewer(palette = "Set1")
###Word Frequency df
Word_Frequency <- structure(list(Word = c("Baby", "Bagel", "Bandage", "Banjo",
"Carriage", "Carrot", "Chicken", "Chipmunk", "City", "Cobra",
"Cocoa", "Fairy", "Ferret", "Garbage", "Garlic", "Letter", "Lettuce",
"Lobster", "Locker", "Marble", "Marker", "Muffin", "Mushroom",
"Pasta", "Peacock", "Peanut", "Possum", "Puppet", "Puppy", "Raccoon",
"Racket", "Rooster", "Ruler", "Sandal", "Sandwich", "Scissors",
"Turkey", "Turtle", "Whistle", "Wizard"), `Frequency (Google Books)` = c(6127799,
29335, 428865, 125242, 2505730, 215525, 1724136, 30591, 30586130,
69450, 382604, 1082454, 115446, 674079, 651590, 20168453, 353798,
256454, 271988, 1996235, 769873, 81982, 270867, 238173, 149644,
277100, 76104, 384574, 316058, 73050, 268584, 136815, 1659585,
81154, 430627, 511265, 1763068, 396105, 778168, 309233), Freq10k = c(612.7799,
2.9335, 42.8865, 12.5242, 250.573, 21.5525, 172.4136, 3.0591,
3058.613, 6.945, 38.2604, 108.2454, 11.5446, 67.4079, 65.159,
2016.8453, 35.3798, 25.6454, 27.1988, 199.6235, 76.9873, 8.1982,
27.0867, 23.8173, 14.9644, 27.71, 7.6104, 38.4574, 31.6058, 7.305,
26.8584, 13.6815, 165.9585, 8.1154, 43.0627, 51.1265, 176.3068,
39.6105, 77.8168, 30.9233)), class = c("grouped_df", "tbl_df",
"tbl", "data.frame"), row.names = c(NA, -40L), groups = structure(list(
Word = c("Baby", "Bagel", "Bandage", "Banjo", "Carriage",
"Carrot", "Chicken", "Chipmunk", "City", "Cobra", "Cocoa",
"Fairy", "Ferret", "Garbage", "Garlic", "Letter", "Lettuce",
"Lobster", "Locker", "Marble", "Marker", "Muffin", "Mushroom",
"Pasta", "Peacock", "Peanut", "Possum", "Puppet", "Puppy",
"Raccoon", "Racket", "Rooster", "Ruler", "Sandal", "Sandwich",
"Scissors", "Turkey", "Turtle", "Whistle", "Wizard"), .rows = structure(list(
1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L, 11L, 12L, 13L,
14L, 15L, 16L, 17L, 18L, 19L, 20L, 21L, 22L, 23L, 24L,
25L, 26L, 27L, 28L, 29L, 30L, 31L, 32L, 33L, 34L, 35L,
36L, 37L, 38L, 39L, 40L), ptype = integer(0), class = c("vctrs_list_of",
"vctrs_vctr", "list"))), class = c("tbl_df", "tbl", "data.frame"
), row.names = c(NA, -40L), .drop = TRUE))
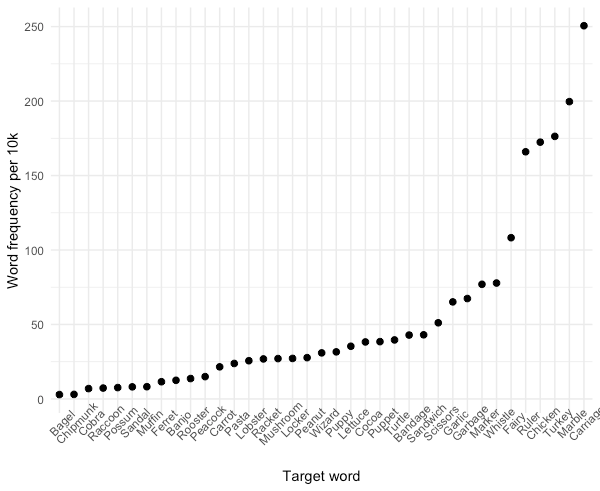
### Word Frequency Plot
Word_Frequency %>%
ggplot(aes(y = Freq10k, x = reorder(Word,Freq10k))) +
labs(y= "Word frequency per 10k", x = "Target word")+
geom_point(size = 2)+
theme_minimal() +
theme(axis.text.x = element_text(angle = 45))+
scale_color_brewer(palette = "Set1")
Thanks in advance.
>Solution :
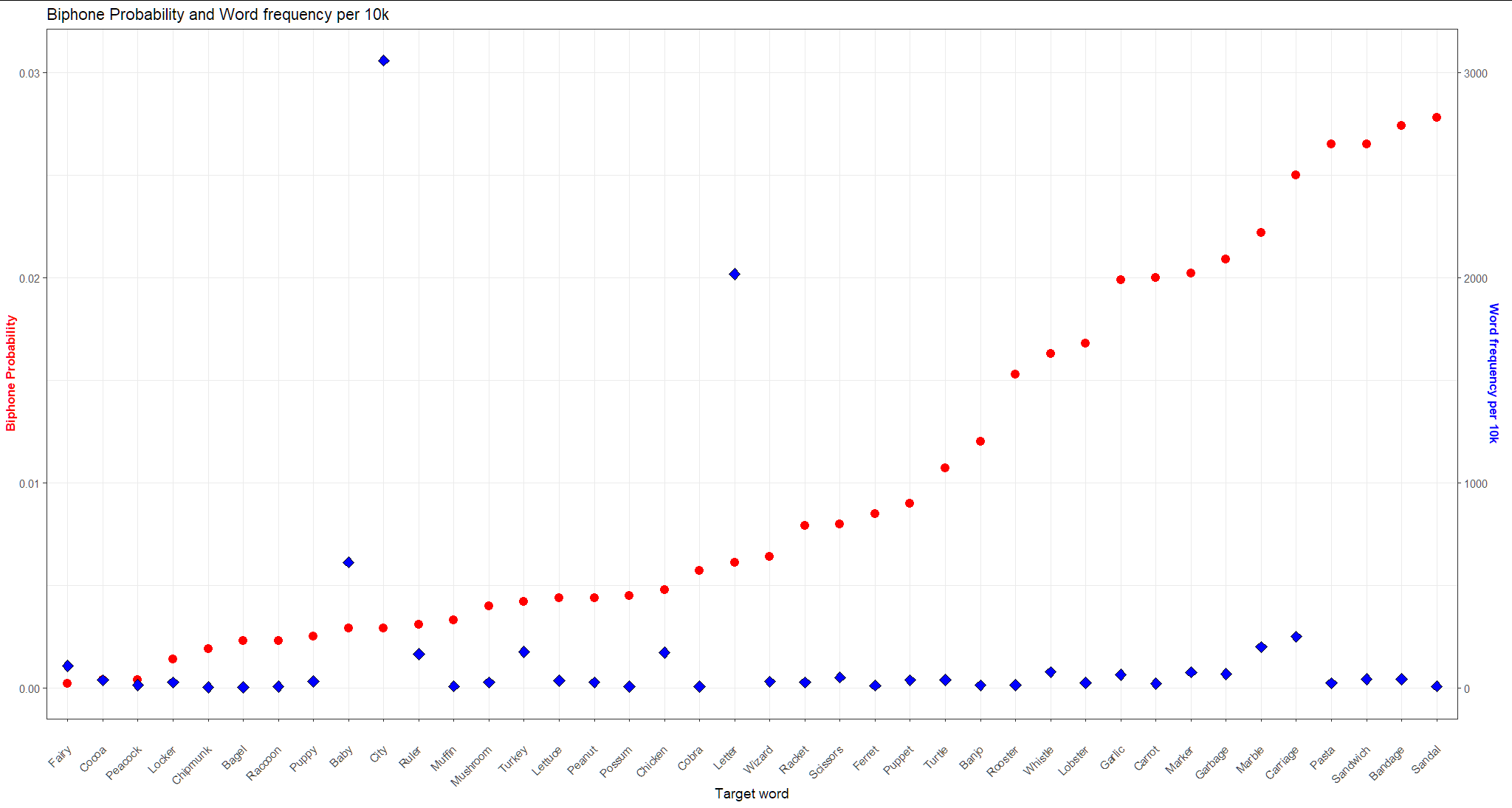
One way could be to use a second y axis. Although this method is to be used critically, in this situation I think it is appropriate:
library(tidyverse)
df <- left_join(Phonotactic_Probability, Word_Frequency, by="Word")
coeff <- 100000
ggplot(df, aes(x = reorder(Word,`Biphone Probability`))) +
geom_point(aes(y = `Biphone Probability`), size = 4, color = "red")+
geom_point(aes(y = Freq10k / coeff), shape=23, fill="blue", size=4) +
scale_y_continuous(
name = "Biphone Probability",
sec.axis = sec_axis(~.*coeff, name = "Word frequency per 10k")
) +
xlab("\nTarget word")+
theme_bw(14)+
theme(
axis.title.y = element_text(color = "red", size=13, face="bold"),
axis.title.y.right = element_text(color = "blue", size=13, face="bold"),
axis.text.x = element_text(angle = 45, vjust = 0.5, hjust=1)
) +
ggtitle("Biphone Probability and Word frequency per 10k")