I’ve been having some difficulty seeing how many time one value exists in the same column but of another df. Here’s what I’m working with:
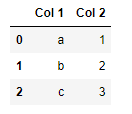
data1 = {
"Col 1": ['a','b','c'],
"Col 2": [1,2,3]
}
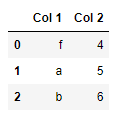
data2 = {
"Col 1": ['f','a','b'],
"Col 2": [4,5,6]
}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
Now I have this block of code to see how many times a value in col 1 in df1 also appears in col 1 of df2. (I only have a col 2 because I want to show how I want to iterate without using iterrows):
count = 0 #Setting the variable count
for row in df1['Col 1']: #Iterating through each row.
if row in df2['Col 1']:
count += 1 #Increasing count by 1 every time there's a repeated value.
print("Count:", count)
When I run this, my count returns as 0, when it should be 2, since both df1[‘Col 1’] and df2[‘Col 2’] both share ‘a’, and ‘b’.
I’m sure this is a minor error, but I’d appreciate a nudge in the right direction. Thanks!
>Solution :
When trying to check if a column contains a certain value in pandas, you need to add .values. Without it, you are creating a splice of the dataframe with the column and the indices, like so:
print(df2['Col 1'])
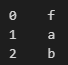
Changing this to print(df2['Col 1'].values) yields a list of the contents of the column: ['f' 'a' 'b'], allowing your if statement to find your strings in that list.
Therefore, updating your code to:
count = 0 #Setting the variable count
for row in df1['Col 1']: #Iterating through each row.
if row in df2['Col 1'].values:
count += 1 #Increasing count by 1 every time there's a repeated value.
print("Count:", count)
Prints out: Count:2, your expected answer. More info on finding values in columns can be found here.