I have a data frame data
data_ = {'ID': [777, 777, 777,777,777,777],'Month':[1,1,1,2,2,2], 'Salary': [130,170,50,140,180,60], 'O': ["AC","BR","BR","AC","BR","BR"], 'D':["LF","AC","LF","LF","AC","LF"], 'B':[True,True,False,True,True,False]}
data = pd.DataFrame(data=data_)
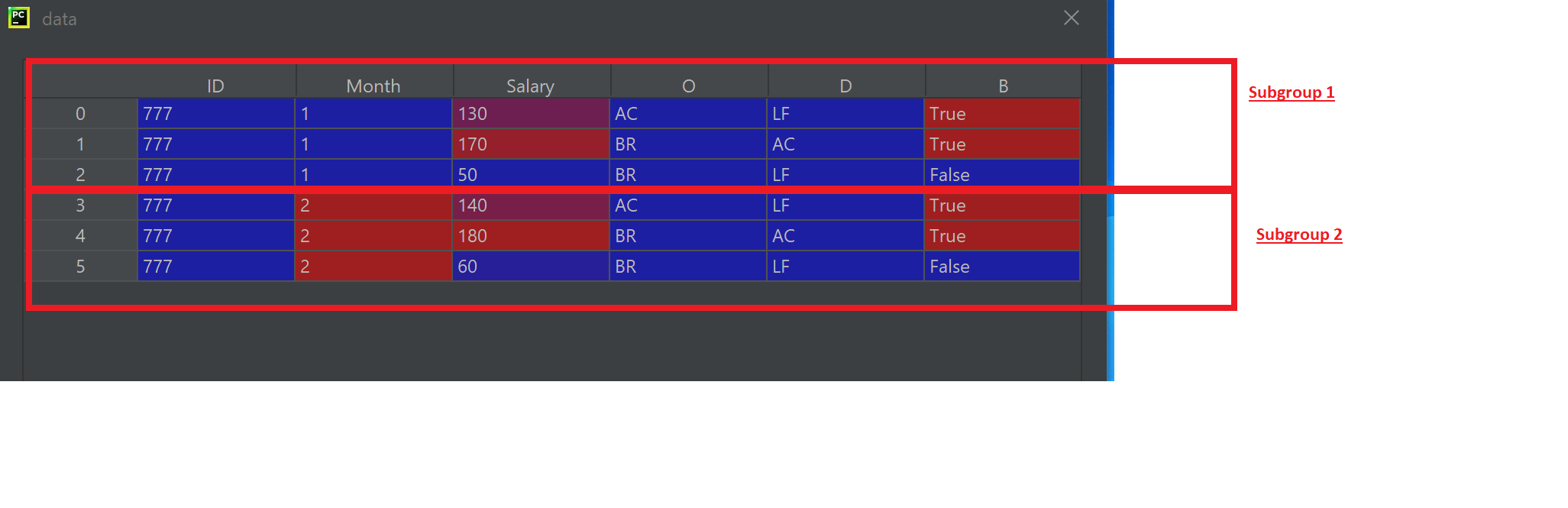
for each subgroup of this data frame:
Subgroup=data.groupby(["ID","Month"])
I would like to add a new column NEW_Salary filled with the values of Salary where B is false in each subgroup as show in the picture below. I don’t know exactly how I can do that

>Solution :
Filter by B False before groupby then join with your initial dataframe
Subgroup = data[~data['B']] \
.groupby(["ID","Month"]) \
.agg(NEW_SALARY = ('Salary', 'mean')) \
.reset_index()
final_df = data.merge(Subgroup, on=['ID', 'Month'])
final_df
Output:
