I have a DataFrame with 3 columns; Date, Values1 and some column with dimensional data. Not relevant for this step, but I need the DataFrame to remain in the granularity as is.
Now I want to create an additional column, Values2, which is a multiplication of the value in Values1.
This multiplication is based on the month of Date and the factor is in an array (with a factor for each month)
d = {'date': ['2022-01-01', '2022-01-01', '2022-02-23','2022-02-23',
'2022-02-27', '2022-03-05','2022-03-05','2022-04-02'],
'col2':['A','B','A','B','A','A','B','A'],
'Value1': [1000, 1010, 900, 1000, 1000, 1010, 1000,1000]}
df = pd.DataFrame(data=d)
month_targets = [1.01,1.011,0.91,1.01,1.01,1.011,0.9,1.01,1.01,1.011,1.009,1.01]
How can I do this in the most efficient/pythonic way?
I don’t think iterating over the month array and for each month iterate over the full dataframe would be ideal. so looking for a better way 😉
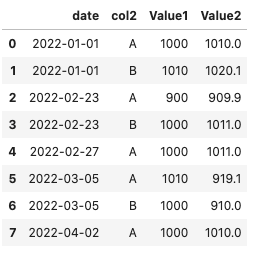
Expected output:
>Solution :
Convert month_target to a dictionary that maps months to target value; then map this dictionary to the months in df. Then multiply it with "Value1" column:
month_target_dict = dict(enumerate(month_targets, 1))
df['date'] = pd.to_datetime(df['date'])
df['Value2'] = df['date'].dt.month.map(month_target_dict) * df['Value1']
Output:
date col2 Value1 Value2
0 2022-01-01 A 1000 1010.0
1 2022-01-01 B 1010 1020.1
2 2022-02-23 A 900 909.9
3 2022-02-23 B 1000 1011.0
4 2022-02-27 A 1000 1011.0
5 2022-03-05 A 1010 919.1
6 2022-03-05 B 1000 910.0
7 2022-04-02 A 1000 1010.0