This is my DataFrame:
import pandas as pd
df = pd.DataFrame(
{
'a': [10, 20, 30, 400, 50, 60],
'b': [897, 9, 33, 4, 55, 65]
}
)
And this is the output that I want. I want to create column c.
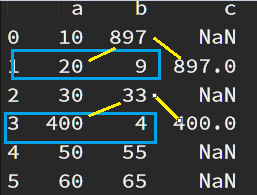
a b c
0 10 897 NaN
1 20 9 897.0
2 30 33 NaN
3 400 4 400.0
4 50 55 NaN
5 60 65 NaN
These are the steps needed:
a) Find rows that df.a > df.b
b) From the above rows compare the value from a to its previous value from b. If it was more than previous b value, put a in column c otherwise put the previous b.
For example:
a) Rows 1 and 3 met df.a > df.b
b) From row 1, 20 is less than 897 so 897 is chosen. However in row 3, 400 is greater than 33 so it is selected.
This image clarifies the point:
This is what I have tried but it does not work:
df.loc[df.a > df.b, 'c'] = max(df.a, df.b.shift(1))
>Solution :
Try:
mask = df.a > df.b
df.loc[mask, "c"] = np.where(df["a"] > df["b"].shift(), df["a"], df["b"].shift())[mask]
print(df)
Prints:
a b c
0 10 897 NaN
1 20 9 897.0
2 30 33 NaN
3 400 4 400.0
4 50 55 NaN
5 60 65 NaN