Based on the learnings about CUDA Graph achieved from my previous question, I am trying to utilize CUDA Graphs for the computation of Fast Fourier Transform (FFT) using CUDA’s cuFFT APIs.
I modified the sample FFT code present on Github into the following FFT code using CUDA Graphs:
#include <cuda.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "device_functions.h"
#include <iostream>
#include <cufft.h>
// Complex data type
typedef float2 Complex;
static __device__ inline Complex ComplexScale(Complex, float);
static __device__ inline Complex ComplexMul(Complex, Complex);
static __global__ void ComplexPointwiseMulAndScale(Complex*, const Complex*, int, float);
#define CUDA_CALL( call ) \
{ \
cudaError_t result = call; \
if ( cudaSuccess != result ) \
std::cerr << "CUDA error " << result << " in " << __FILE__ << ":" << __LINE__ << ": " << cudaGetErrorString( result ) << " (" << #call << ")" << std::endl; \
}
#define CUDA_FFT_CALL( call ) \
{ \
cufftResult result = call; \
if ( CUFFT_SUCCESS != result ) \
std::cerr << "FFT error " << result << " in " << __FILE__ << ":" << __LINE__ << ": " << result << std::endl; \
}
// The filter size is assumed to be a number smaller than the signal size
#define SIGNAL_SIZE 10
#define FILTER_KERNEL_SIZE 4
static __device__ inline Complex ComplexScale(Complex a, float s)
{
Complex c;
c.x = s * a.x;
c.y = s * a.y;
return c;
}
// Complex multiplication
static __device__ inline Complex ComplexMul(Complex a, Complex b)
{
Complex c;
c.x = a.x * b.x - a.y * b.y;
c.y = a.x * b.y + a.y * b.x;
return c;
}
// Complex pointwise multiplication
static __global__ void ComplexPointwiseMulAndScale(Complex* a, const Complex* b, int size, float scale)
{
const int numThreads = blockDim.x * gridDim.x;
const int threadID = blockIdx.x * blockDim.x + threadIdx.x;
for (int i = threadID; i < size; i += numThreads)
{
a[i] = ComplexScale(ComplexMul(a[i], b[i]), scale);
}
}
int main()
{
printf("[simpleCUFFT] is starting...\n");
int minRadius = FILTER_KERNEL_SIZE / 2;
int maxRadius = FILTER_KERNEL_SIZE - minRadius;
int padded_data_size = SIGNAL_SIZE + maxRadius;
// Allocate HOST Memories
Complex* h_signal = (Complex*)malloc(sizeof(Complex) * SIGNAL_SIZE); //host signal
Complex* h_filter_kernel = (Complex*)malloc(sizeof(Complex) * FILTER_KERNEL_SIZE); //host filter
Complex* h_padded_signal= (Complex*)malloc(sizeof(Complex) * padded_data_size); // host Padded signal
Complex* h_padded_filter_kernel = (Complex*)malloc(sizeof(Complex) * padded_data_size); // host Padded filter kernel
Complex* h_convolved_signal = (Complex*)malloc(sizeof(Complex) * padded_data_size); // to store convolution RESULTS
memset(h_convolved_signal, 0, padded_data_size * sizeof(Complex));
//Allocate DEVICE Memories
Complex* d_signal; //device signal
cudaMalloc((void**)&d_signal, sizeof(Complex) * padded_data_size);
Complex* d_filter_kernel;
cudaMalloc((void**)&d_filter_kernel, sizeof(Complex) * padded_data_size); //device kernel
//CUDA GRAPH
bool graphCreated = false;
cudaGraph_t graph;
cudaGraphExec_t instance;
cudaStream_t stream;
cudaStreamCreate(&stream);
// CUFFT plan
cufftHandle plan;
CUDA_FFT_CALL(cufftPlan1d(&plan, padded_data_size, CUFFT_C2C, 1));
cufftSetStream(plan, stream); // bind plan to the stream
// Initalize the memory for the signal
for (unsigned int i = 0; i < SIGNAL_SIZE; ++i)
{
h_signal[i].x = rand() / (float)RAND_MAX;
h_signal[i].y = 0;
}
// Initalize the memory for the filter
for (unsigned int i = 0; i < FILTER_KERNEL_SIZE; ++i)
{
h_filter_kernel[i].x = rand() / (float)RAND_MAX;
h_filter_kernel[i].y = 0;
}
//REPEAT 3 times
int nRepeatationsNeeded = 3;
for (int repeatations = 0; repeatations < nRepeatationsNeeded; repeatations++)
{
std::cout << "\n\n" << "Repeatation ------ " << repeatations << std::endl;
if (!graphCreated)
{
//Start Graph Recording --------------!!!!!!!!
CUDA_CALL(cudaStreamBeginCapture(stream, cudaStreamCaptureModeGlobal));
//Pad Data
CUDA_CALL(cudaMemcpyAsync(h_padded_signal + 0, h_signal, SIGNAL_SIZE * sizeof(Complex), cudaMemcpyHostToHost, stream));
memset(h_padded_signal + SIGNAL_SIZE, 0, (padded_data_size - SIGNAL_SIZE) * sizeof(Complex));
//CUDA_CALL(cudaMemsetAsync(h_padded_signal + SIGNAL_SIZE, 0, (padded_data_size - SIGNAL_SIZE) * sizeof(Complex), stream));
CUDA_CALL(cudaMemcpyAsync(h_padded_filter_kernel + 0, h_filter_kernel + minRadius, maxRadius * sizeof(Complex), cudaMemcpyHostToHost, stream));
/*CUDA_CALL(cudaMemsetAsync(h_padded_filter_kernel + maxRadius, 0, (padded_data_size - FILTER_KERNEL_SIZE) * sizeof(Complex), stream));*/
memset(h_padded_filter_kernel + maxRadius, 0, (padded_data_size - FILTER_KERNEL_SIZE) * sizeof(Complex));
CUDA_CALL(cudaMemcpyAsync(h_padded_filter_kernel + padded_data_size - minRadius, h_filter_kernel, minRadius * sizeof(Complex), cudaMemcpyHostToHost, stream));
// MemCpy H to D
CUDA_CALL(cudaMemcpyAsync(d_signal, h_padded_signal, sizeof(Complex) * padded_data_size, cudaMemcpyHostToDevice, stream)); //Signal
CUDA_CALL(cudaMemcpyAsync(d_filter_kernel, h_padded_filter_kernel, sizeof(Complex) * padded_data_size, cudaMemcpyHostToDevice, stream)); //Kernel
//COMPUTE FFT
CUDA_FFT_CALL(cufftExecC2C(plan, (cufftComplex*)d_signal, (cufftComplex*)d_signal, CUFFT_FORWARD)); // Transform signal
CUDA_FFT_CALL(cufftExecC2C(plan, (cufftComplex*)d_filter_kernel, (cufftComplex*)d_filter_kernel, CUFFT_FORWARD)); // Transform kernel
ComplexPointwiseMulAndScale << <64, 1, 0, stream >> > (d_signal, d_filter_kernel, padded_data_size, 1.0f / padded_data_size); // Multiply and normalize
CUDA_CALL(cudaGetLastError());
CUDA_FFT_CALL(cufftExecC2C(plan, (cufftComplex*)d_signal, (cufftComplex*)d_signal, CUFFT_INVERSE)); // Transform signal back
// Copy device memory to host
CUDA_CALL(cudaMemcpyAsync(h_convolved_signal, d_signal, sizeof(Complex) * padded_data_size, cudaMemcpyDeviceToHost, stream));
//END Graph Recording
CUDA_CALL(cudaStreamEndCapture(stream, &graph));
CUDA_CALL(cudaGraphInstantiate(&instance, graph, NULL, NULL, 0));
graphCreated = true;
}
else
{
CUDA_CALL(cudaGraphLaunch(instance, stream));
CUDA_CALL(cudaStreamSynchronize(stream));
}
//verify results
for (int i = 0; i < SIGNAL_SIZE; i++)
std::cout << "index: " << i << ", fft: " << h_convolved_signal[i].x << std::endl;
}
//Destroy CUFFT context
cufftDestroy(plan);
// cleanup memory
cudaStreamDestroy(stream);
free(h_signal);
free(h_filter_kernel);
free(h_padded_signal);
free(h_padded_filter_kernel);
cudaFree(d_signal);
cudaFree(d_filter_kernel);
return 0;
}
PROBLEM: The Output of the above program is below, in which it can be seen that the values of the result are also ZEROS for the first iteration. How can I resolve this?
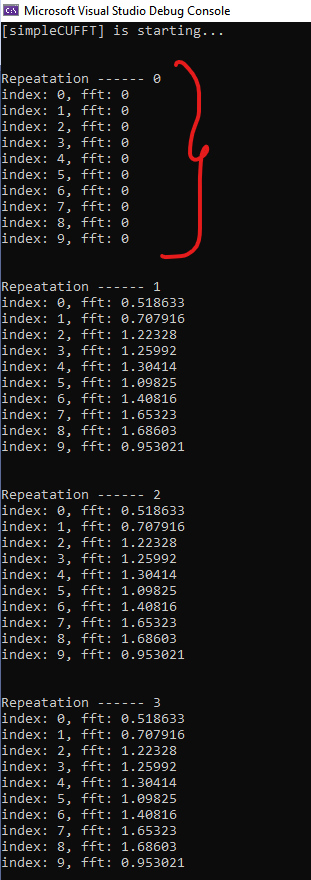
>Solution :
The results are zero for the first iteration, because for the first iteration, the work is all issued in capture mode.
In capture mode, no CUDA work actually gets done. From here:
When a stream is being captured, work launched into the stream is not enqueued for execution.
I pointed you to this same area of the documentation in a comment to your last question. You might wish to read the entire programming guide section on graphs, and there are also blogs available.