In the fictitious data here, I want to identify any customers who did not purchase alcoholic beverages (specifically "Beer" or "Wine" in example) across all visits combined.
df = pd.DataFrame({"customer": ['A55', 'A55', 'A55',
'B080', 'B080',
'D900', 'D900',
'Z900', 'Z900', 'Z900', 'Z900'],
"date":['01/11/2016', '01/21/2016', '02/11/2016',
'08/17/2016', '6/17/2016',
'03/01/2016','04/30/2016',
'05/16/2016','09/27/2016', '10/05/2016', '11/11/2016'],
"item": ['Beer', 'Beer', 'Wine',
'Coffee', 'Gatorade',
'Wine', 'Coffee',
'Beer', 'Wine', 'Beer', 'Coffee']
})
##Tag visit number for each customer
df["customer_visit_number"] = df.groupby("customer").cumcount().add(1)
In the dataframe example below, only customer B080 never bought any Beer or Wine. By contrast the others bought Beer or Wine on occasion or all visits. To tag customer visits I added a cumcount() operation but not all customers visit the store same number of times.
Is there a simple way in pandas to filter all rows associated with this customer only after doing the groupby operation at customer level?
See dataframe below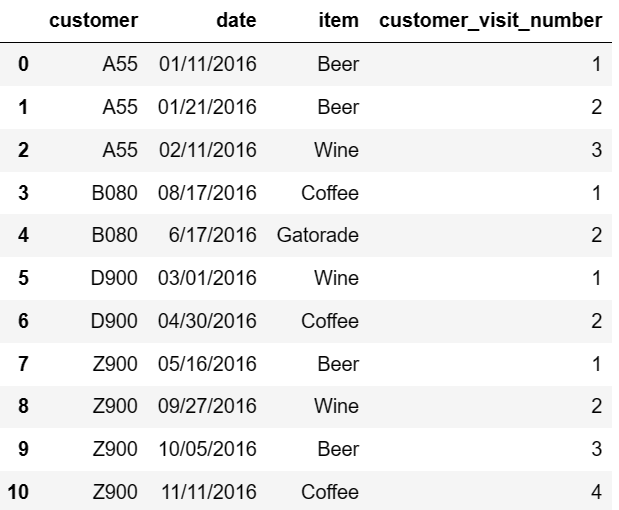
>Solution :
Identify customers that purchased alcoholic beverages:
drop = (df['item'].isin(['Beer', 'Wine'])
.groupby(df['customer']).any()
)
Filter with boolean indexing:
out = df[~df['customer'].isin(drop[drop].index)]
Or with groupby.transform to directly obtain a Series of booleans for boolean indexing:
m = (df['item'].isin(['Beer', 'Wine'])
.groupby(df['customer'])
.transform('any')
)
out = df[~m]
Output:
customer date item
3 B080 08/17/2016 Coffee
4 B080 6/17/2016 Gatorade
Intermediates:
# drop
customer
A55 True
B080 False
D900 True
Z900 True
Name: item, dtype: bool
# m
0 True
1 True
2 True
3 False
4 False
5 True
6 True
7 True
8 True
9 True
10 True
Name: item, dtype: bool