I’m trying to find the % total of the value within its respective index level, however, the current result is producing Nan values.
pd.DataFrame({"one": np.arange(0, 20), "two": np.arange(20, 40)}, index=[np.array([np.zeros(10), np.ones(10).flatten()], np.arange(80, 100)])
DataFrame:
one two
0.0 80 0 20
81 1 21
82 2 22
83 3 23
84 4 24
85 5 25
86 6 26
87 7 27
88 8 28
89 9 29
1.0 90 10 30
91 11 31
92 12 32
93 13 33
94 14 34
95 15 35
96 16 36
97 17 37
98 18 38
99 19 39
Aim:
To see the % total of a column ‘one’ within its respective level.
Excel example:
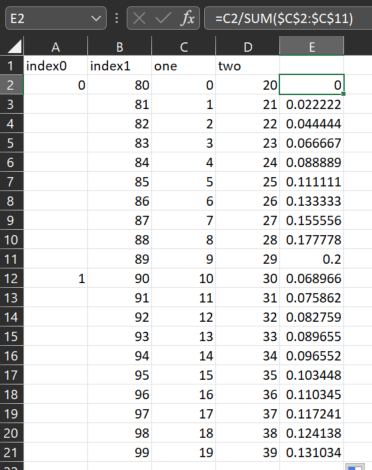
Current attempted code:
for loc in df.index.get_level_values(0):
df.loc[loc, 'total'] = df.loc[loc, :] / df.loc[loc, :].sum()
>Solution :
IIUC, use:
df['total'] = df['one'].div(df.groupby(level=0)['one'].transform('sum'))
output:
one two total
0 80 0 20 0.000000
81 1 21 0.022222
82 2 22 0.044444
83 3 23 0.066667
84 4 24 0.088889
85 5 25 0.111111
86 6 26 0.133333
87 7 27 0.155556
88 8 28 0.177778
89 9 29 0.200000
1 90 10 30 0.068966
91 11 31 0.075862
92 12 32 0.082759
93 13 33 0.089655
94 14 34 0.096552
95 15 35 0.103448
96 16 36 0.110345
97 17 37 0.117241
98 18 38 0.124138
99 19 39 0.131034