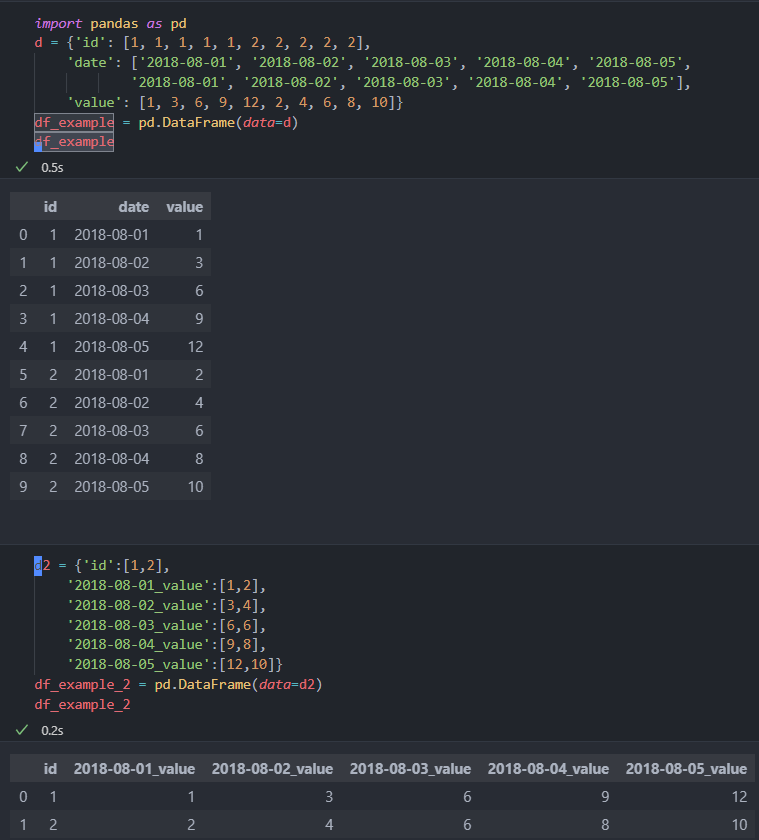
I have the following pandas.DataFrame object with the following columns: id, date, and value.
It’s created with the following code.
import pandas as pd
d = {'id': [1, 1, 1, 1, 1, 2, 2, 2, 2, 2],
'date': ['2018-08-01', '2018-08-02', '2018-08-03', '2018-08-04', '2018-08-05',
'2018-08-01', '2018-08-02', '2018-08-03', '2018-08-04', '2018-08-05'],
'value': [1, 3, 6, 9, 12, 2, 4, 6, 8, 10]}
df_example = pd.DataFrame(data=d)
df_example
However since the values for id are repeated (1, and 2), I need to flatten this dataframe where
I only have one row for every id. A desirable output would be like the following code. Note that new columns names are made of the value from date, concatenated with the ‘value’ column name.
d2 = {'id':[1,2],
'2018-08-01_value':[1,2],
'2018-08-02_value':[3,4],
'2018-08-03_value':[6,6],
'2018-08-04_value':[9,8],
'2018-08-05_value':[12,10]}
df_example_2 = pd.DataFrame(data=d2)
df_example_2
My question is: How could I accomplish this without using group by. I tried the latter, and also trying to transpose the data frame but I could not succeeded.
>Solution :
df_example.pivot(index='id',columns='date',values='value')