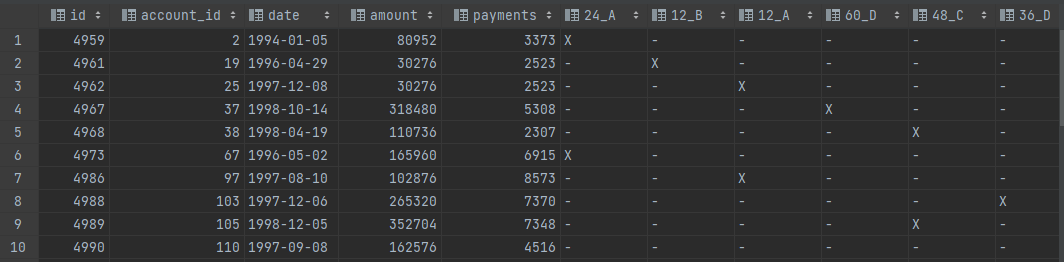
I have a .csv that looks like the below. I was wondering what the best way would be to keep the first few cols (id, account_id, date, amount, payments) intact while creating a new column containing the column name for observations with an ‘X’ marked.
The first 10 rows of the csv look like:
id,account_id,date,amount,payments,24_A,12_B,12_A,60_D,48_C,36_D,36_C,12_C,48_A,24_C,60_C,24_B,48_D,24_D,48_B,36_A,36_B,60_B,12_D,60_A
4959,2,1994-01-05,80952,3373,X,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-
4961,19,1996-04-29,30276,2523,-,X,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-
4962,25,1997-12-08,30276,2523,-,-,X,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-
4967,37,1998-10-14,318480,5308,-,-,-,X,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-
4968,38,1998-04-19,110736,2307,-,-,-,-,X,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-
4973,67,1996-05-02,165960,6915,X,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-
4986,97,1997-08-10,102876,8573,-,-,X,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-
4988,103,1997-12-06,265320,7370,-,-,-,-,-,X,-,-,-,-,-,-,-,-,-,-,-,-,-,-
4989,105,1998-12-05,352704,7348,-,-,-,-,X,-,-,-,-,-,-,-,-,-,-,-,-,-,-,-
4990,110,1997-09-08,162576,4516,-,-,-,-,-,-,X,-,-,-,-,-,-,-,-,-,-,-,-,-
>Solution :
There used to be something called lookup but that’s been deprecated in favor of melt.
The idea is to use the id_vars as the grouping, and all the other columns get smashed into a single column with their respective value. Then filter where that value is X, effectively dropping the other rows.
import pandas as pd
df = pd.read_csv('test.txt')
df = df.melt(id_vars=['id','account_id','date','amount','payments'], var_name='x_col')
df = df.loc[df['value']=='X'].drop(columns='value')
print(df)
Output
id account_id date amount payments x_col
0 4959 2 1994-01-05 80952 3373 24_A
5 4973 67 1996-05-02 165960 6915 24_A
11 4961 19 1996-04-29 30276 2523 12_B
22 4962 25 1997-12-08 30276 2523 12_A
26 4986 97 1997-08-10 102876 8573 12_A
33 4967 37 1998-10-14 318480 5308 60_D
44 4968 38 1998-04-19 110736 2307 48_C
48 4989 105 1998-12-05 352704 7348 48_C
57 4988 103 1997-12-06 265320 7370 36_D
69 4990 110 1997-09-08 162576 4516 36_C