I want to download multiple pdf files of old newspapers. Specifically files that look like this or this. My problem is that when I try to automate this process with requests or wget, because the sites don’t give you an actual pdf file, I am not able to get the actual file.
Is there a way to automate this process and download the actual files with Python?
>Solution :
For this particular web page the pages are served from a predictable url:
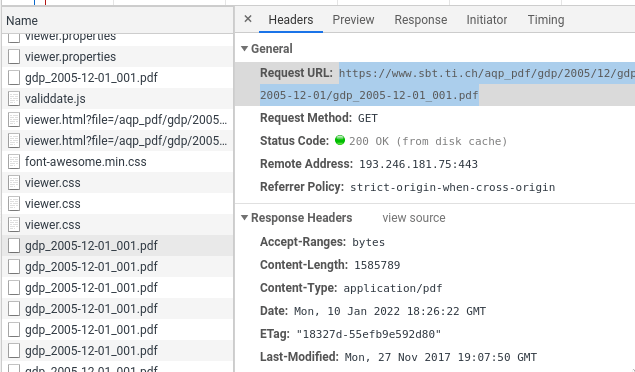
- https://www.sbt.ti.ch/aqp_pdf/gdp/2005/12/gdp_2005-12-01/gdp_2005-12-01_001.pdf
- https://www.sbt.ti.ch/aqp_pdf/gdp/2005/12/gdp_2005-12-01/gdp_2005-12-01_002.pdf
- etc
This is so regular I wouldn’t even bother extracting it from the page for this problem: I’d just generate the url myself, do a requests.get() for each of them, and splice them together with PyPdf2.
The more general question is: how did I know that url? Have a look at your browser’s devtools:
General approaches
There are basically two solutions to this kind of problem:
- extract the required parameters from the page (look at how the page builds up the urls it needs), or
- run a real browser with something like selenium, and automate it.
Sometimes you get lucky and there’s a real api designed to help you do this. It’s quite common when looking at public archive data like this (in France, the apis of the BNF are excellent, but I don’t know what, if anything, would be the Italian equivalent).