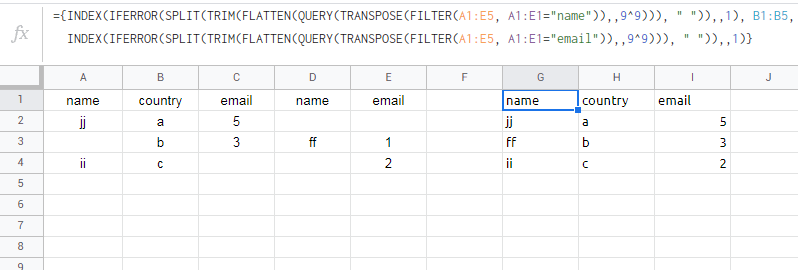
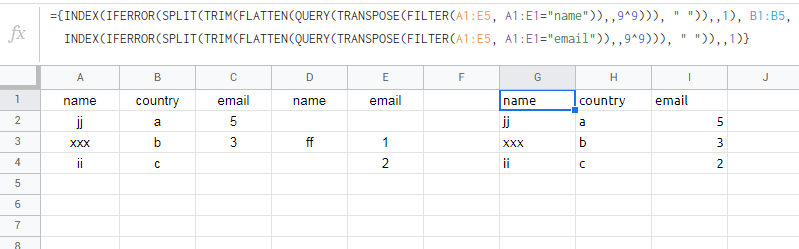
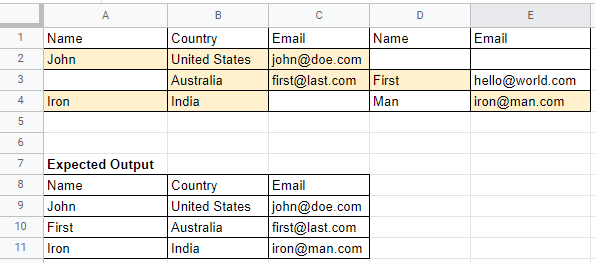
I need to get the first occurrence from duplicate column headers as follows:
A workaround was to group all the same columns and use an IF blank then get next column formula. However, it seems not efficient if a column was added in between or the columns were re-arranged in some way. So the quickest way I could think of is to just get the first occurrence from a range that’s equal to the column header.
>Solution :
first column:
=INDEX(FILTER(A1:E5, A1:E1="name"),,1)
first non empty:
=INDEX(IFERROR(SPLIT(TRIM(FLATTEN(QUERY(TRANSPOSE(
FILTER(A1:E5, A1:E1="name")),,9^9))), " ")),,1)
whole table:
={INDEX(IFERROR(SPLIT(TRIM(FLATTEN(QUERY(TRANSPOSE(FILTER(A1:E5, A1:E1="name")),,9^9))), " ")),,1), B1:B5,
INDEX(IFERROR(SPLIT(TRIM(FLATTEN(QUERY(TRANSPOSE(FILTER(A1:E5, A1:E1="email")),,9^9))), " ")),,1)}