I have a data frame, I want to group the data based on the ids and then stick the values for each id together. However, since the number of the ids are not equal, I have to fill the missing values for those ids with mean of the day before.
I have provided an example as below, for example, for id=1, id=2 there is two dates, but for id=3, there are three days.
df = pd.DataFrame()
df['id'] = [1, 1, 2,2, 3, 3, 3]
df['date'] = ['2019-01-01', '2019-01-03', '2019-01-01','2019-01-02', '2019-01-01', '2019-01-02','2019-01-03']
df['val1'] = [10, 100, 20, 30, 40, 50, 60]
df['val2'] = [30, 30, -20, -30, -40,-50, -60 ]
df['val3'] = [50, 10, 120, 300, 140, 150, 160]
I have tried with the following code:
DF_sticked = df.filter(regex='val\d+', axis=1).groupby(df['id'])\
.apply(np.ravel).apply(pd.Series).rename(lambda x: f"val{x}", axis=1).reset_index().fillna(0)
But, in the above code, I fill the missing value with 0. And also the missing value are at the end of the columns.
The output that I want is as follow. As you can see, the val 4, val5, val 6 of id=1 is same as the mean of the day before. or the val 7, 8, 9 of id=2 is equal to the mean of the day before (mean of 30, -30, 300)
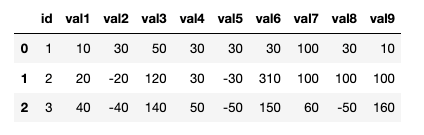
Thank you so much.
>Solution :
You can actually pivot the dataframe, then then groupy the dates, transform('mean'), and ffill:
tmp = df.pivot(index='id', columns='date').swaplevel(axis=1).sort_index(axis=1)
tmp[tmp.isna()] = tmp.groupby(level=0, axis=1).transform('mean').ffill(axis=1)
tmp = tmp.astype(int).droplevel(0, axis=1)
# Fix the columns
tmp = tmp.set_axis(np.arange(1, tmp.shape[1] + 1).astype(str), axis=1).add_prefix('val')
Output:
>>> tmp
val1 val2 val3 val4 val5 val6 val7 val8 val9
id
1 10 30 50 30 30 30 100 30 10
2 20 -20 120 30 -30 300 100 100 100
3 40 -40 140 50 -50 150 60 -60 160