Dataframe below that I want to compare the sub-strings in rows under GroupBy.
For example, in Project_A, it’s to compare Project_A’s first row [‘William’, ‘Oliver’, ‘Elijah’, ‘Liam’] with Project_A’s second row [ ‘James’, ‘Mason’, ‘Elijah’, ‘Oliver’]
Ideal result as:
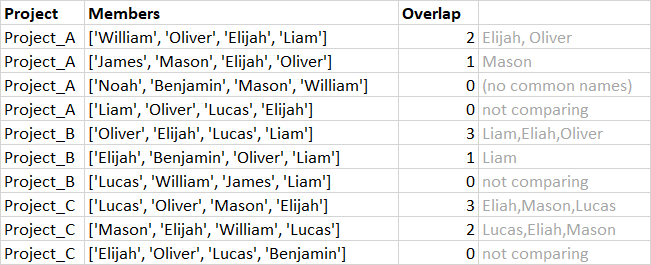
I’ve tried to convert the rows in list, then compare them, but unsuccessful.
import pandas as pd
from io import StringIO
import numpy as np
csvfile = StringIO(
"""
Project Members
Project_A 'William', 'Oliver', 'Elijah', 'Liam'
Project_A 'James', 'Mason', 'Elijah', 'Oliver'
Project_A 'Noah', 'Benjamin', 'Mason', 'William'
Project_A 'Liam', 'Oliver', 'Lucas', 'Elijah'
Project_B 'Oliver', 'Elijah', 'Lucas', 'Liam'
Project_B 'Elijah', 'Benjamin', 'Oliver', 'Liam'
Project_B 'Lucas', 'William', 'James', 'Liam'
Project_C 'Lucas', 'Oliver', 'Mason', 'Elijah'
Project_C 'Mason', 'Elijah', 'William', 'Lucas'
Project_C 'Elijah', 'Oliver', 'Lucas', 'Benjamin'
""")
df = pd.read_csv(csvfile, sep = '\t', engine='python')
df['Overlaps'] = df.groupby('Project').apply(lambda group: len(set(group['Members'].tolist()) & set(group['Members'].shift(1).tolist()))).tolist()
What’s the right way to do so? Thank you.
>Solution :
Pandas approach
# encode the unqiue values in Membors as indiator columns
s = df['Members'].str.get_dummies(sep=', ')
# shift the indicators per project and multiply
# to calculate the intersection with the previous row
overlaps = s * s.groupby(df['Project']).shift(-1)
# Sum along axis 1 to calculate overlap count
df['overlaps'] = overlaps.sum(axis=1)
Result
Project Members overlaps
0 Project_A 'William', 'Oliver', 'Elijah', 'Liam' 2.0
1 Project_A 'James', 'Mason', 'Elijah', 'Oliver' 1.0
2 Project_A 'Noah', 'Benjamin', 'Mason', 'William' 0.0
3 Project_A 'Liam', 'Oliver', 'Lucas', 'Elijah' 0.0
4 Project_B 'Oliver', 'Elijah', 'Lucas', 'Liam' 3.0
5 Project_B 'Elijah', 'Benjamin', 'Oliver', 'Liam' 1.0
6 Project_B 'Lucas', 'William', 'James', 'Liam' 0.0
7 Project_C 'Lucas', 'Oliver', 'Mason', 'Elijah' 3.0
8 Project_C 'Mason', 'Elijah', 'William', 'Lucas' 2.0
9 Project_C 'Elijah', 'Oliver', 'Lucas', 'Benjamin' 0.0