Using the following code i am reading a csv file into a dataframe and convert the time column ‘object’ into a ‘datetime’ format.
# Use the read_csv function to create a DataFrame from the CSV file
shackles = pd.read_csv(path_data_shackles, delimiter=';')
print(shackles.dtypes)
# Convert time column to datetime column
shackles['time'] = pd.to_datetime(pd.Series(shackles['time']), format="%H:%M:%S:%f")
print('')
print(shackles['time'].iloc[3688])
print('')
print(shackles.dtypes)
Which outputs the following:
DataTag object
ms_Elapsed int64
Value object
time object
dtype: object
2023-05-02 10:54:00.760000
DataTag object
ms_Elapsed int64
Value object
time datetime64[ns]
dtype: object
The problem is that it reads 10:54:00:76 as 10:54:00:760 instead of 10:54:00:076.
Which causes my graph to look weird as shown in the picture.
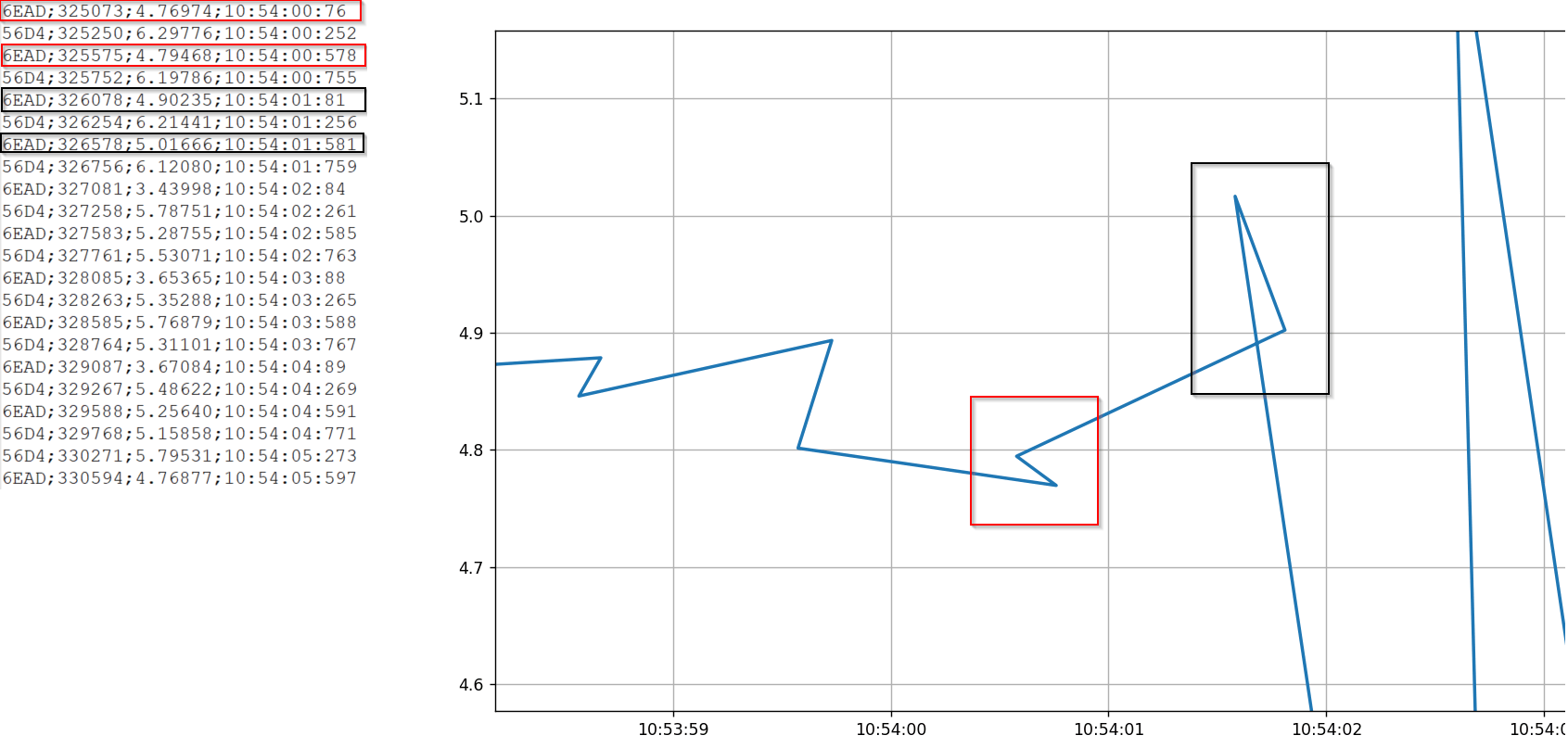
I tried converting the time column into a string column first so i can fill zeros infront of the digits to make it 3 digits total.However i was unable to convert it into a string column in the first place. Someone got any other idea’s on how to tackle this problem?
>Solution :
You can pre-process your string with str.replace and zfill to correctly pad the last digits:
df['time'] = pd.to_datetime(
df['time'].str.replace('(\d+)$', lambda m: m.group(1).zfill(3),
regex=True),
format='%H:%M:%S:%f')
Alternatively, with str.split:
tmp = df['time'].str.rsplit(':', n=1, expand=True)
df['time'] = pd.to_datetime(tmp[0]+':'+tmp[1].str.zfill(3), format='%H:%M:%S:%f')
Example output:
0 1900-01-01 10:54:00.076
1 1900-01-01 10:54:00.252
Name: time, dtype: datetime64[ns]
Used input:
df = pd.DataFrame({'time': ['10:54:00:76', '10:54:00:252']})