I have a use case wherein I have 7 columns. But 1st 4 columns are in one DF and rest 3 in 2nd DF. Below is the sample code where I have defined them
import pandas as pd
df1 = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['A', 'B', 'C'],
'col3': [4.5, 6.7, 8.9],
'col4': ['X', 'Y', 'Z']
})
df2 = pd.DataFrame({
'col5': ['apple', 'banana', 'cherry'],
'col6': [10, 20, 30],
'col7': [True, False, True]
})
# Concatenate vertically
result_df = pd.concat([df1, df2], axis=0, ignore_index=True)
# Save to Excel
result_df.to_excel('output.xlsx', index=False)
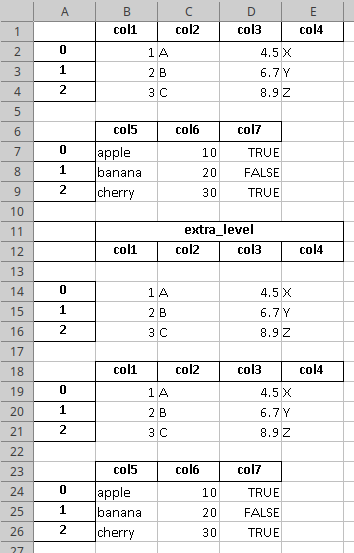
So, I want to insert the data in below format
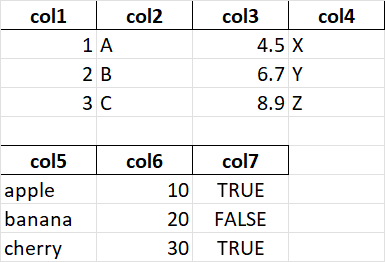
But ,no matter what I do I am not able to get this format. I actual output is as below

It seems more of a Pandas limitations to me. I there any work around to achieve the required result.? please suggest
>Solution :
You shouldn’t use concat (which will create a single DataFrame), but rather write the two DataFrames independently.
Use pandas.ExcelWriter to handle the file:
# create new excel file
writer = pd.ExcelWriter('output.xlsx')
# write first DataFrame
df1.to_excel(writer, index=False)
# we start to write after the first table
# skipping 1 row (= len(df)+2)
df2.to_excel(writer, startrow=len(df1)+2, index=False)
# close file
writer.close()
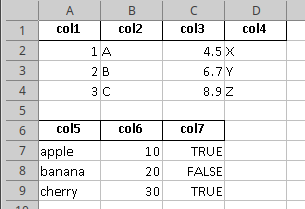
generalization
If you have many dataframes you can generalize with:
dfs = [df1, df2, df1, df2]
skip = 1
writer = pd.ExcelWriter('output.xlsx')
start = 0
for df in dfs:
df.to_excel(writer, startrow=start, index=False)
start += len(df)+skip+1
writer.close()
NB. this is assuming the columns only have one level.
Output:
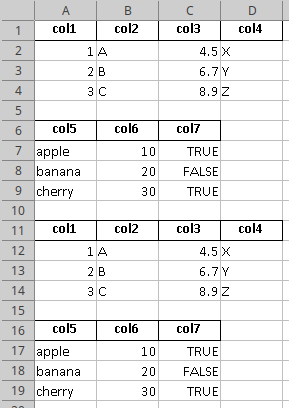
For a MultiIndex you must also save the index:
dfs = [df1, df2, pd.concat({'extra_level': df1}, axis=1), df1, df2]
skip = 1
writer = pd.ExcelWriter('output.xlsx')
start = 0
for df in dfs:
df.to_excel(writer, startrow=start, index=True)
start += len(df)+skip+df.columns.nlevels+(df.columns.nlevels>1)
Output: