I have data that looks like this
df = pd.DataFrame({'ID': [1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2],
'DATE': ['1/1/2015','1/2/2015', '1/3/2015','1/4/2015','1/5/2015','1/6/2015','1/7/2015','1/8/2015',
'1/9/2016','1/2/2015','1/3/2015','1/4/2015','1/5/2015','1/6/2015','1/7/2015'],
'CD': ['A','A','A','A','B','B','A','A','C','A','A','A','A','A','A']})
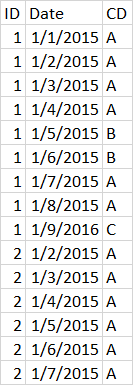
What I would like to do is group by ID and CD and get the start and stop change for each change. I tried using groupby and agg function but it will group all A together even though they needs to be separated since there is B in between 2 A.
df1 = df.groupby(['ID','CD'])
df1 = df1.agg(
Start_Date = ('Date',np.min),
End_Date=('Date', np.min)
).reset_index()
What I get is :
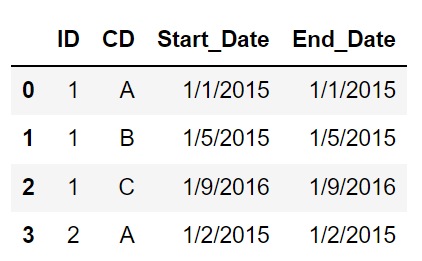
I was hoping if some one could help me get the result I need. What I am looking for is :
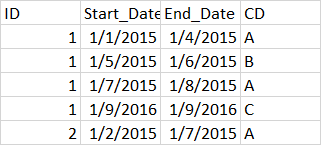
>Solution :
make grouper for grouping
grouper = df['CD'].ne(df['CD'].shift(1)).cumsum()
grouper:
0 1
1 1
2 1
3 1
4 2
5 2
6 3
7 3
8 4
9 5
10 5
11 5
12 5
13 5
14 5
Name: CD, dtype: int32
then use groupby with grouper
df.groupby(['ID', grouper, 'CD'])['DATE'].agg([min, max]).droplevel(1)
output:
min max
ID CD
1 A 1/1/2015 1/4/2015
B 1/5/2015 1/6/2015
A 1/7/2015 1/8/2015
C 1/9/2016 1/9/2016
2 A 1/2/2015 1/7/2015
change column name and use reset_index and so on..for your desired output
(df.groupby(['ID', grouper, 'CD'])['DATE'].agg([min, max]).droplevel(1)
.set_axis(['Start_Date', 'End_Date'], axis=1)
.reset_index()
.assign(CD=lambda x: x.pop('CD')))
result
ID Start_Date End_Date CD
0 1 1/1/2015 1/4/2015 A
1 1 1/5/2015 1/6/2015 B
2 1 1/7/2015 1/8/2015 A
3 1 1/9/2016 1/9/2016 C
4 2 1/2/2015 1/7/2015 A