I have a 2D boolean numpy array, mask:
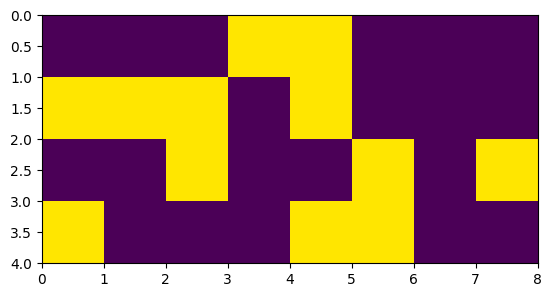
array([[False, False, False, True, True, False, False, False],
[ True, True, True, False, True, False, False, False],
[False, False, True, False, False, True, False, True],
[ True, False, False, False, True, True, False, False]])
mask was generated by:
np.random.seed(43210)
mask = (np.random.rand(4,8)>0.7)
I visualize mask via:
plt.pcolormesh(mask)
plt.gca().invert_yaxis()
plt.gca().set_aspect('equal')
Result:
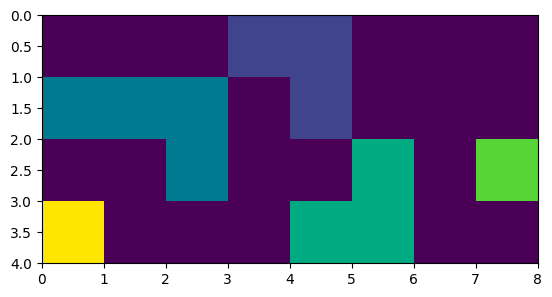
I use scipy.ndimage.label to label the features, ie sections of neighbouring True elements in the array.
label, num_features = scipy.ndimage.label(mask)
label is then:
array([[0, 0, 0, 1, 1, 0, 0, 0],
[2, 2, 2, 0, 1, 0, 0, 0],
[0, 0, 2, 0, 0, 3, 0, 4],
[5, 0, 0, 0, 3, 3, 0, 0]], dtype=int32)
visualization:
However, I would like to have an array where the features are marked by an number showing the size of the feature. I achieve this by:
newlabel = np.zeros(label.shape)
for i in range(1,num_features+1): # works but very slow
newlabel[label==i]=sum((label==i).flatten())
newlabel is then:
array([[0., 0., 0., 3., 3., 0., 0., 0.],
[4., 4., 4., 0., 3., 0., 0., 0.],
[0., 0., 4., 0., 0., 3., 0., 1.],
[1., 0., 0., 0., 3., 3., 0., 0.]])
visualization:
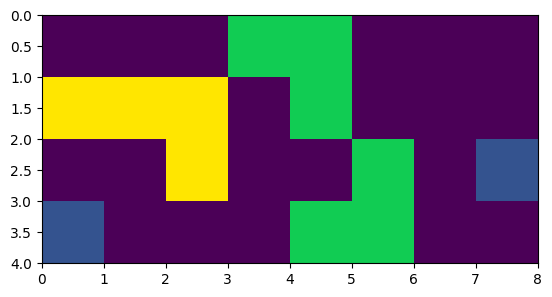
This result above (the newlabel array) is correct, this is what I want. The features with only 1 pixel are marked by 1. (blue squares in the visualization). Features with 3 pixels are marked by 3. (green shapes on plot), while the feature with 4 pixels are marked by 4. in newlabel (yellow shape on plot).
The problem with this approach is that the for loop takes a long time when mask is big. Testing with a 100 times larger mask:
import time
np.random.seed(43210)
mask = (np.random.rand(40,80)>0.7)
t0 = time.time()
label, num_features = scipy.ndimage.label(mask)
t1 = time.time()
newlabel = np.zeros(label.shape)
for i in range(1,num_features+1):
newlabel[label==i]=sum((label==i).flatten())
t2 = time.time()
print(f"Initial labelling takes: {t1-t0} seconds.")
print(f"Relabelling by feature size takes: {t2-t1} seconds.")
print(f"Relabelling takes {(t2-t1)/(t1-t0)} times as much time as original labelling.")
Output:
Initial labelling takes: 0.00052642822265625 seconds.
Relabelling by feature size takes: 0.3239290714263916 seconds.
Relabelling takes 615.333786231884 times as much time as original labelling.
This makes my solution unviable on real world examples.
How can I label the features by their size faster?
>Solution :
You could use numpy.unique:
n, idx, cnt = np.unique(label, return_inverse=True, return_counts=True)
n2, idx2 = np.unique(cnt, return_inverse=True)
out = np.where(mask, n2[idx2][idx].reshape(mask.shape), 0)
Output:
array([[0, 0, 0, 3, 3, 0, 0, 0],
[4, 4, 4, 0, 3, 0, 0, 0],
[0, 0, 4, 0, 0, 3, 0, 1],
[1, 0, 0, 0, 3, 3, 0, 0]])