I have a pandas DataFrame that looks:
df=pd.DataFrame({'user': ['user 1', 'user 4', 'user 1', 'user 4', 'user 1', 'user 4'],
'group': [0, 0, 1, 1, 2, 2],
'x1': [0.9, 0.9, 0.7, 0.7, 0.4, 0.4],
'x2': [0.759740, 1.106061, 0.619357, 1.260234, 0.540633, 1.437956]})
output:
user group x1 x2
0 user 1 0 0.9 0.759740
1 user 4 0 0.9 1.106061
2 user 1 1 0.7 0.619357
3 user 4 1 0.7 1.260234
4 user 1 2 0.4 0.540633
5 user 4 2 0.4 1.437956
I want to return each user with a condition if x2 is below x1 then return this row and if there is no row that meets this condition when x2 is below x1 then return this user with a change group number to 10.
For example: for the user1, row number 2 should be selected since it returns a min value of x2 below x1 1 and even row 4 has a min value of x2 but x2 is higher than x1. for user 4, all x2 higher than x1 for all rows, so we change group number for min value of x2 to number 10.
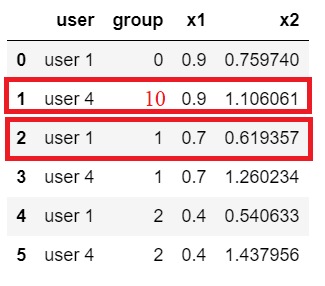
The expected output:

>Solution :
Use:
df2 = (df[df['x2'].lt(df['x1'])]
.set_index('group')
.groupby('user')['x2']
.idxmin()
.reindex(df['user'].unique(), fill_value=10)
.reset_index(name='group'))
print (df2)
user group
0 user 1 1
1 user 4 10
How it working:
First filter rows by condition in boolean indexing:
print (df[df['x2'].lt(df['x1'])])
user group x1 x2
0 user 1 0 0.9 0.759740
2 user 1 1 0.7 0.619357
Then get group names by minimal x2 per groups by DataFrameGroupBy.idxmin, so used DataFrame.set_index:
print (df[df['x2'].lt(df['x1'])].set_index('group'))
user x1 x2
group
0 user 1 0.9 0.759740
1 user 1 0.7 0.619357
And then add missing users by unique values in Series.reindex:
print (df[df['x2'].lt(df['x1'])].set_index('group').groupby('user')['x2'].idxmin())
user
user 1 1
Name: x2, dtype: int64
print (df[df['x2'].lt(df['x1'])].set_index('group')
.groupby('user')['x2'].idxmin()
.reindex(df['user'].unique(), fill_value=10))
user
user 1 1
user 4 10
Name: x2, dtype: int64
And last create 2 columns DataFrame by Series.reset_index.