I have a column where each row contains a list of strings of varying lengths. I need to create a new column that has a list of booleans (equivalent to the original list) of whether or not each element is found in ANOTHER (larger) list.
This is what I am doing and well, it clearly does not work. I based it off of this question:
How to return list of booleans to see if elements of one list in another list
data = [
[1, ["cat", "cat", "mouse"]],
[2, ["dog", "horse"]],
[3, ["cat"]],
[
4,
np.nan,
],
]
df = pd.DataFrame(data, columns=["ID", "list"])
df
main_list = ["cat", "dog", "mouse", "pig", "cow"]
df["contains_item_from_list"] = df["list"].apply(
(lambda x: [x in main_list for x in b])
)
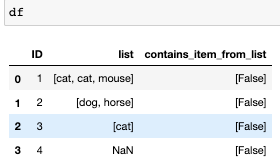
desired output:
ID list contains_item_from_list
1 [cat,cat,mouse] [True, True, True]
2 [dog,horse] [True, False]
3 [cat] [True]
4 NaN [False]
>Solution :
You can also apply a function that iterates over each list in list. This should be faster than exploding the column:
main_set = set(main_list)
df["contains_item_from_list"] = df['list'].apply(lambda x: [w in main_set for w in x] if isinstance(x, list) else [x in main_set])
Output:
ID list contains_item_from_list
0 1 [cat, cat, mouse] [True, True, True]
1 2 [dog, horse] [True, False]
2 3 [cat] [True]
3 4 NaN [False]