In a data.frame, I would like to add a column that identifies groups of consecutive days.
I think I need to start by converting my strings to date format…
Here’s my example :
mydf <- data.frame(
var_name = c(rep("toto",6),rep("titi",5)),
date_collection = c("09/12/2022","10/12/2022","13/12/2022","16/12/2022","16/12/2022","17/12/2022",
"01/12/2022","03/11/2022","04/11/2022","05/11/2022","08/11/2022")
)
Expected output :
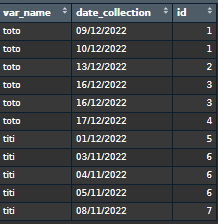
>Solution :
Convert to Date class and do the adjacent diff to create a a logical vector and take the cumulative sum
library(dplyr)
library(lubridate)
mydf %>%
mutate(id = cumsum(c(0, abs(diff(dmy(date_collection)))) > 1)+1)