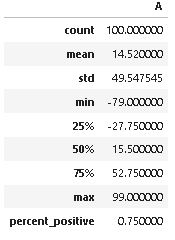
Per the code below, I have created a df with a single column (labeled ‘A’) of numerical data.
- I then use the pandas .describe() function to get summary statistics for the df.
- I save the output from the .describe() function to a new dataframe, called df_stats.
- I next calculate the percentage of time the data in the original df is positive and save this as ‘Percent_Positive’.
- I want to add a row to df_stats that is called ‘percent_positive’ and populates column A in this new row with the value calculated as ‘Percent_Positive’.
However, when I do the steps described above per the code below, a new row is added to df_stats (which I want), but a new column is also added to df_stats (which I do not want). This new column includes NaN values for all rows, other than the final (new) ‘percent_positive’ row, which includes the ‘Percent_Positive’ value I calculated previously.
Can someone please tell me how to populate df_stats with the Percent_Positive value without adding a new column to df_stats? Thank you.
# Import dependencies
import pandas as pd
import numpy as np
# Create df with randomly populated numbers.
df = pd.DataFrame(np.random.randint(-80,100,size=(100, 1)), columns=list('A'))
# Use the .describe function to calculate basic stats on the df.
df_stats = df.describe()
# Create new var to calculate the percentage of time a value in column A is positive.
Percent_Positive = df_stats.loc[df_stats['A'] > 0,'A'].count()/df_stats['A'].count()
# Add new row to df_stats called 'percent_positive' using the Percent_Positive var above.
df_stats = df_stats.append(pd.Series(Percent_Positive, name='percent_positive'))
display(df_stats)
>Solution :
Use:
# Import dependencies
import pandas as pd
import numpy as np
# Create df with randomly populated numbers.
df = pd.DataFrame(np.random.randint(-80,100,size=(100, 1)), columns=list('A'))
# Use the .describe function to calculate basic stats on the df.
df_stats = df.describe()
# Create new var to calculate the percentage of time a value in column A is positive.
Percent_Positive = df_stats.loc[df_stats['A'] > 0,'A'].count()/df_stats['A'].count()
# A DF WITH THE SAME COLS.######################################
df_stats = df_stats.append(pd.DataFrame({'A':[Percent_Positive]}, index=['percent_positive']))
display(df_stats)
The result: