I have seen multiple posts asking this question but have been unable to get the to work with my dataset.
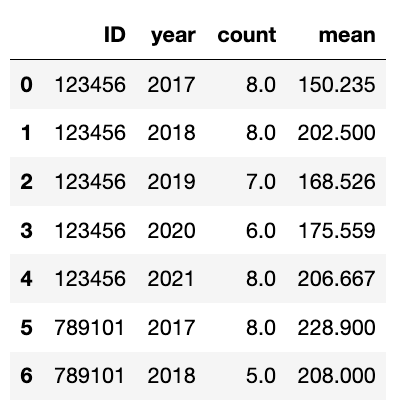
I have a dataframe containing summary information (output from a .groupby and describe() operation).
data = [
[123456, "2017", 8.0, 150.235],
[123456, "2018", 8.0, 202.5],
[123456, "2019", 7.0, 168.526],
[123456, "2020", 6.0, 175.559],
[123456, "2021", 8.0, 206.667],
[789101, "2017", 8.0, 228.9],
[789101, "2018", 5.0, 208]
]
df = pd.DataFrame(
data,
columns=[
"ID",
"year",
"count",
"mean",
],
)
df
I am trying to do 2 things:
- Calculate the percentage change within
IDfromyeartoyear. - Calculate the percentage change across
ID, i.e from the firstyearto the latestyearwhat is the overall percentage change.
Things I’ve tried:
df["pct_ch"] = df.groupby(["ID", "year"])["mean"].apply(pd.Series.pct_change) + 1as suggested here, unfortunately this returns a column of allNaN.df["pct_change"] = df.groupby(["ID", "year"])["mean"].pct_change(-1)as suggested here, which also returns a column of allNaNvalues.
I am curious what I am doing wrong (why am I getting all NaN and how I can calculate these percentage change columns?
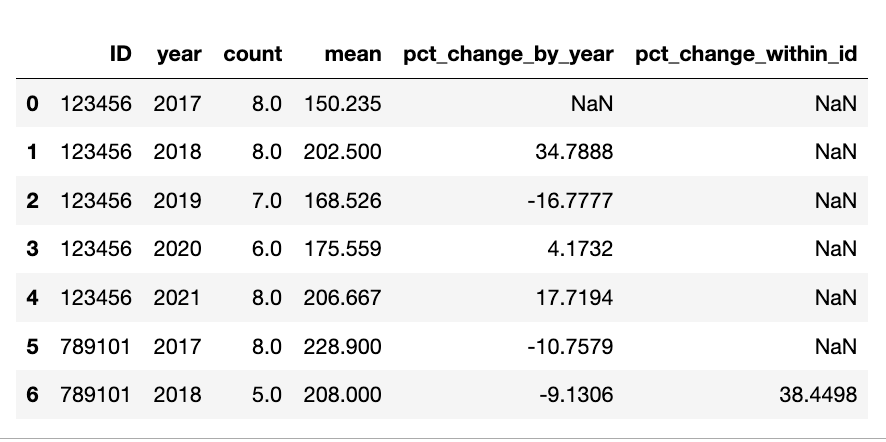
Ideal output would look something like this:
>Solution :
You shouldn’t group by year, and you can just groupby.pct_change directly:
df['pct_ch'] = df.groupby('ID')['mean'].pct_change()
By setting year as group, you groups contain only one row, and there is nothing to compute.
Output:
ID year count mean pct_ch
0 123456 2017 8.0 150.235 NaN
1 123456 2018 8.0 202.500 0.347888
2 123456 2019 7.0 168.526 -0.167773
3 123456 2020 6.0 175.559 0.041732
4 123456 2021 8.0 206.667 0.177194
5 789101 2017 8.0 228.900 NaN
6 789101 2018 5.0 208.000 -0.091306
For the overall percentage change use a custom function:
df['pct_ch_overall'] = df.groupby('ID')['mean']. transform(lambda g: g.iloc[[0, -1]].pct_change())
Output:
ID year count mean pct_ch pct_ch_overall
0 123456 2017 8.0 150.235 NaN NaN
1 123456 2018 8.0 202.500 0.347888 NaN
2 123456 2019 7.0 168.526 -0.167773 NaN
3 123456 2020 6.0 175.559 0.041732 NaN
4 123456 2021 8.0 206.667 0.177194 0.375625
5 789101 2017 8.0 228.900 NaN NaN
6 789101 2018 5.0 208.000 -0.091306 -0.091306