I have a data like this:
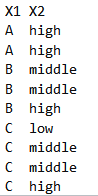
how to change become:

I need some helps to fit it…
>Solution :
Here is a dplyr option
library(dplyr)
df %>%
group_by(X1) %>%
summarise(
X3 = names(sort(table(X2), decreasing = TRUE))[1],
X2 = toString(X2),
.groups = "drop") %>%
select(X1, X2, X3)
## A tibble: 3 × 3
# X1 X2 X3
# <chr> <chr> <chr>
#1 A high, high high
#2 B middle, middle, high middle
#3 C low, middle, middle, high middle
Note: Since you’re overwriting X2, we need to carry out the calculation for X3 first and then summarise X2. The last select call reorders columns to match your expected output.
Note also that this might need some careful checking of edge cases on your side to deal with ties in word frequencies.
Sample data
df <- data.frame(
X1 = c("A", "A", "B", "B", "B", "C", "C", "C", "C"),
X2 = c("high", "high", "middle", "middle", "high", "low", "middle", "middle", "high"))