I have this dataset
> dput(head(data, 130))
structure(list(ID = 1:130, Gender = structure(c(1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2), format.spss = "F32.3", labels = c(Women = 1,
Men = 2), class = c("haven_labelled", "vctrs_vctr", "double")),
Education = structure(c(1, 2, 2, 2, 2, 2, 2, 2, 2, 1, 1,
1, 1, 2, 2, 1, 2, 1, 2, 2, 1, 2, 2, 2, 2, 1, 2, 1, 1, 2,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 3,
2, 1, 1, 1, 1, 1, 1, 1, 3, 2, 2, 2, 2, 2, 2, 2, 2, 3, 2,
2, 3, 2, 2, 2, 3, 2, 3, 1, 3, 1, 2, 2, 2, 2, 2, 1, 1, 2,
2, 2, 1, 1, 2), format.spss = "F32.3", labels = c(Basic = 1,
Medium = 2, Higher = 3), class = c("haven_labelled", "vctrs_vctr",
"double")), Avoiding = structure(c(9, 10, 12, 10, 13, 11,
10, 8, 5, 6, 7, 8, 12, 6, 9, 10, 9, 11, 9, 13, 11, 10, 10,
14, 13, 9, 8, 11, 7, 13, 6, 8, 10, 10, 9, 11, 8, 5, 8, 12,
9, 9, 11, 9, 10, 10, 8, 9, 9, 10, 8, 9, 8, 9, 10, 9, 14,
8, 5, 11, 5, 7, 14, 8, 11, 8, 9, 9, 8, 15, 9, 6, 8, 10, 9,
9, 10, 12, 8, 8, 8, 13, 8, 11, 9, 9, 5, 13, 8, 7, 10, 10,
12, 10, 5, 3, 9, 9, 5, 6, 7, 8, 7, 6, 8, 6, 7, 16, 7, 10,
7, 7, 5, 4, 11, 16, 6, 9, 10, 10, 5, 9, 9, 7, 9, 12, 11,
10, 8, 10), format.spss = "F16.2"), Coping = structure(c(12,
8, 11, 12, 12, 8, 14, 5, 7, 12, 10, 15, 10, 7, 7, 7, 13,
7, 9, 12, 13, 11, 11, 15, 7, 5, 5, 10, 12, 13, 4, 8, 10,
8, 7, 9, 9, 9, 7, 5, 9, 7, 8, 8, 10, 9, 11, 7, 8, 10, 11,
6, 8, 10, 7, 9, 10, 10, 6, 7, 10, 12, 13, 9, 13, 8, 9, 11,
6, 6, 7, 8, 6, 13, 12, 9, 15, 11, 10, 10, 9, 8, 4, 13, 7,
6, 13, 9, 15, 12, 13, 11, 8, 8, 9, 12, 14, 12, 8, 11, 5,
9, 10, 9, 9, 12, 7, 11, 6, 13, 8, 9, 9, 5, 14, 16, 13, 10,
7, 14, 9, 9, 10, 8, 8, 13, 9, 14, 11, 14), format.spss = "F16.2"),
Obtaining = structure(c(15, 14, 17, 18, 16, 11, 20, 18, 11,
16, 19, 22, 20, 14, 15, 21, 19, 15, 16, 22, 19, 15, 18, 19,
20, 13, 16, 22, 20, 22, 20, 14, 15, 21, 13, 15, 14, 14, 18,
17, 19, 12, 12, 19, 17, 15, 14, 16, 18, 11, 17, 17, 15, 16,
11, 18, 13, 16, 12, 17, 15, 18, 21, 18, 18, 10, 14, 15, 15,
22, 16, 20, 14, 16, 21, 17, 14, 18, 11, 15, 15, 14, 12, 16,
16, 12, 7, 19, 16, 14, 16, 16, 14, 16, 15, 7, 16, 14, 12,
14, 15, 17, 16, 15, 15, 15, 13, 11, 7, 19, 17, 18, 16, 6,
20, 22, 14, 19, 19, 16, 18, 19, 12, 15, 18, 15, 16, 17, 13,
12), format.spss = "F16.2"), Savoring = structure(c(20, 22,
25, 21, 22, 11, 21, 19, 15, 18, 23, 24, 19, 20, 20, 22, 19,
24, 22, 22, 24, 19, 19, 25, 25, 22, 19, 16, 24, 24, 22, 17,
19, 23, 21, 19, 21, 23, 23, 24, 24, 16, 21, 21, 17, 19, 17,
22, 20, 15, 16, 21, 17, 18, 19, 21, 17, 18, 23, 21, 13, 17,
24, 14, 19, 21, 21, 19, 20, 24, 21, 20, 20, 20, 18, 22, 17,
16, 21, 18, 16, 18, 21, 16, 19, 19, 10, 23, 19, 16, 18, 14,
12, 18, 17, 7, 24, 15, 21, 16, 11, 17, 21, 17, 15, 21, 12,
14, 12, 14, 16, 16, 19, 19, 18, 19, 18, 14, 20, 15, 20, 19,
16, 18, 14, 18, 16, 20, 18, 16), format.spss = "F16.2"),
Efficacy = structure(c(24, 24, 29, 28, 29, 22, 30, 26, 16,
22, 26, 30, 32, 20, 24, 31, 28, 26, 25, 35, 30, 25, 28, 33,
33, 22, 24, 33, 27, 35, 26, 22, 25, 31, 22, 26, 22, 19, 26,
29, 28, 21, 23, 28, 27, 25, 22, 25, 27, 21, 25, 26, 23, 25,
21, 27, 27, 24, 17, 28, 20, 25, 35, 26, 29, 18, 23, 24, 23,
37, 25, 26, 22, 26, 30, 26, 24, 30, 19, 23, 23, 27, 20, 27,
25, 21, 12, 32, 24, 21, 26, 26, 26, 26, 20, 10, 25, 23, 17,
20, 22, 25, 23, 21, 23, 21, 20, 27, 14, 29, 24, 25, 23, 10,
31, 38, 20, 28, 29, 26, 23, 28, 21, 22, 27, 27, 27, 27, 21,
22), format.spss = "F16.2")), row.names = c(NA, -130L), class = c("tbl_df",
"tbl", "data.frame"), na.action = structure(146:422, .Names = c("146",
"147", "148", "149", "150", "151", "152", "153", "154", "155",
"156", "157", "158", "159", "160", "161", "162", "163", "164",
"165", "166", "167", "168", "169", "170", "171", "172", "173",
"174", "175", "176", "177", "178", "179", "180", "181", "182",
"183", "184", "185", "186", "187", "188", "189", "190", "191",
"192", "193", "194", "195", "196", "197", "198", "199", "200",
"201", "202", "203", "204", "205", "206", "207", "208", "209",
"210", "211", "212", "213", "214", "215", "216", "217", "218",
"219", "220", "221", "222", "223", "224", "225", "226", "227",
"228", "229", "230", "231", "232", "233", "234", "235", "236",
"237", "238", "239", "240", "241", "242", "243", "244", "245",
"246", "247", "248", "249", "250", "251", "252", "253", "254",
"255", "256", "257", "258", "259", "260", "261", "262", "263",
"264", "265", "266", "267", "268", "269", "270", "271", "272",
"273", "274", "275", "276", "277", "278", "279", "280", "281",
"282", "283", "284", "285", "286", "287", "288", "289", "290",
"291", "292", "293", "294", "295", "296", "297", "298", "299",
"300", "301", "302", "303", "304", "305", "306", "307", "308",
"309", "310", "311", "312", "313", "314", "315", "316", "317",
"318", "319", "320", "321", "322", "323", "324", "325", "326",
"327", "328", "329", "330", "331", "332", "333", "334", "335",
"336", "337", "338", "339", "340", "341", "342", "343", "344",
"345", "346", "347", "348", "349", "350", "351", "352", "353",
"354", "355", "356", "357", "358", "359", "360", "361", "362",
"363", "364", "365", "366", "367", "368", "369", "370", "371",
"372", "373", "374", "375", "376", "377", "378", "379", "380",
"381", "382", "383", "384", "385", "386", "387", "388", "389",
"390", "391", "392", "393", "394", "395", "396", "397", "398",
"399", "400", "401", "402", "403", "404", "405", "406", "407",
"408", "409", "410", "411", "412", "413", "414", "415", "416",
"417", "418", "419", "420", "421", "422"), class = "omit"))
and I would like to fill this table.
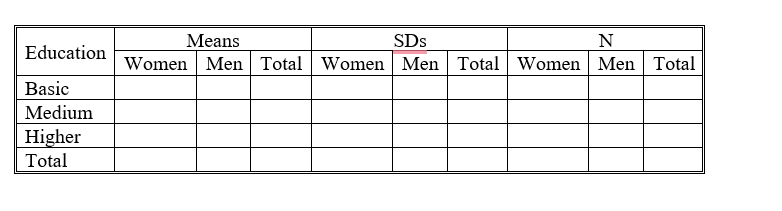
I got the value to fill it as you see here below.
data %>%
group_by(Education, Gender) %>%
summarise(n = n(),
mean = mean(Savoring),
sd = sd(Savoring)) %>%
mutate(tot_n = colSums(across(n)),
tot_mean = colMeans(across(mean)),
tot_sd = colMeans(across(sd)))
data%>%
group_by(Education) %>%
summarise(n = n(),
mean = mean(Savoring),
sd = sd(Savoring))
data%>%
group_by(Gender) %>%
summarise(n = n(),
mean = mean(Savoring),
sd = sd(Savoring))
mean(data$Savoring)
sd(data$Savoring)
Anyway, I do not know whether it is possible to do it by using just a unique chunk encoded in dplyr, but I was wondering whether there is a way to get such value differently without no typing different chunks of code as I did.
Could you just let me know, please?
Thanks
>Solution :
The table you are showing has nested headers, which is not possible in an R data frame. Instead, we can splice the gender name to the statistic name.
Using tidyverse, we can do this as follows:
data %>%
mutate(Gender = names(attributes(Gender)$labels)[Gender],
Education = names(attributes(Education)$labels[Education])) %>%
select(ID, Gender, Education, Savoring) %>%
group_by(Education) %>%
mutate(mean_total = mean(Savoring),
sd_total = sd(Savoring),
n_total = n()) %>%
group_by(Education, Gender) %>%
summarize(mean = mean(Savoring),
sd = sd(Savoring),
n = n(),
mean_total = mean(mean_total),
sd_total = mean(sd_total),
n_total = mean(n_total)) %>%
pivot_wider(names_from = 'Gender', values_from = mean:n) %>%
select(c(1, 6, 5, 2, 8, 7, 3, 10, 9, 4)) %>%
as.data.frame()
#> Education mean_Women mean_Men mean_total sd_Women sd_Men sd_total n_Women n_Men n_total
#> 1 Basic 19.50704 18.00000 19.38961 2.936826 1.264911 2.866117 71 6 77
#> 2 Higher 10.66667 17.00000 14.28571 4.041452 2.449490 4.461475 3 4 7
#> 3 Medium 19.45455 16.38462 18.58696 3.800419 2.599310 3.745077 33 13 46