I have a list with multiple squared dataframes each representing the economy of a country. I would like to combine all the dataframes in a single dataframe with the data of each country on the diagonal cells corresponding to the same column and row names.
Here is a toy setup:
# toy IO
df1 <- data.frame (a1=rnorm(3),
b1=rnorm(3)+2,
c1=rnorm(3)*2)
rownames(df1) <- colnames(df1)
df2 <- data.frame (a2=rnorm(3),
b2=rnorm(3)+5,
c2=rnorm(3)*5)
rownames(df2) <- colnames(df2)
df3 <- data.frame (a3=rnorm(3),
b3=rnorm(3)+10,
c3=rnorm(3)*10)
rownames(df3) <- colnames(df3)
IO <- list(df1,df2,df3)
# initialize the MRIO
# 3*3=9
bigmat <- matrix(NA, 9,9)
dim(bigmat)
bigmat <- as.data.frame(bigmat)
# input row and col names
colnames(bigmat) <- c(colnames(df1),colnames(df2),colnames(df3))
rownames(bigmat) <- colnames(bigmat)
And here what I ideally want. Of course in the original problem I have 214 variables by 25 dataframes, so I would like to have an automated solution.
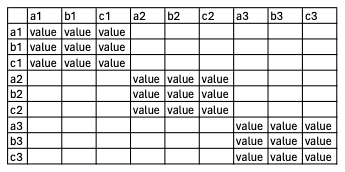
>Solution :
This is a good time for a for() loop. You can assign to your big matrix by the row and column names of the data frames in your list, IO.
for (dat in IO) bigmat[rownames(dat), colnames(dat)] <- dat
bigmat
# a1 b1 c1 a2 b2 c2 a3 b3 c3
# a1 -0.7022840 0.8113511 0.947473 NA NA NA NA NA NA
# b1 -1.3965466 1.1572675 1.251534 NA NA NA NA NA NA
# c1 -0.7046801 2.4452599 -1.759129 NA NA NA NA NA NA
# a2 NA NA NA -0.02525984 4.706425 -2.7166644 NA NA NA
# b2 NA NA NA -0.99340937 4.087659 -2.2857446 NA NA NA
# c2 NA NA NA 1.14106869 6.175546 -0.5993501 NA NA NA
# a3 NA NA NA NA NA NA 2.11147819 10.124772 -1.458151
# b3 NA NA NA NA NA NA 0.95736185 8.755218 2.136663
# c3 NA NA NA NA NA NA 0.01153827 9.380493 2.745363
Alternatively if you want to do it a more idiomatic way for R, you can achieve the same output with Reduce():
Reduce(
\(bigmat, dat) {
bigmat[rownames(dat), colnames(dat)] <- dat
bigmat
},
IO,
init = bigmat
)
### ^^ same results
I think your question implies the row and columns are already in the correct order in each data frame. Nevertheless, an advantage of this approach is that regardless of order, we’re joining on names, so if one of your data frames has columns c("b1", "a1", "c1"), they’ll still end up in the right place in bigmat.